LangSmith, RAGAS & LLM-as-a-Judge: The State of LLM Eval in 2026
Get an email when we publish a new post. No account needed, unsubscribe anytime.
The eval-tool "market" is tiny — and concentrated
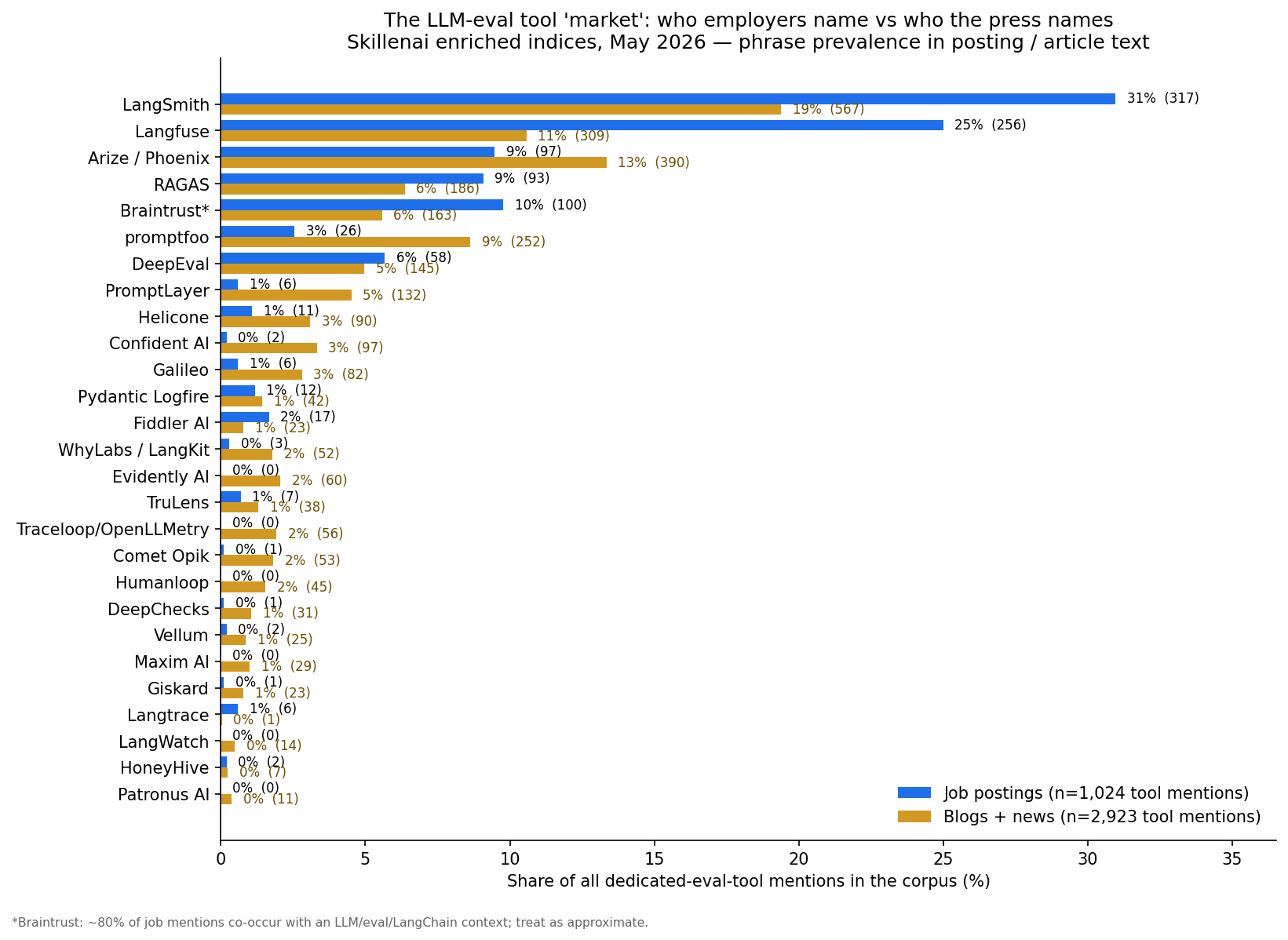
Among job postings that name any dedicated eval or eval-capable observability tool:
| Tool | Job postings | Share of eval-tool mentions |
|---|---|---|
| LangSmith | 317 | 31% |
| Langfuse | 256 | 25% |
| Braintrust* | ~100 | 10% |
| Arize / Phoenix | 97 | 9% |
| RAGAS | 93 | 9% |
| DeepEval | 58 | 6% |
| promptfoo | 26 | 2% |
| Fiddler AI | 17 | 2% |
| Pydantic Logfire | 12 | 1% |
| Helicone | 11 | 1% |
| everything else (Comet/Opik, Evidently AI, Galileo, Patronus AI, TruLens, Giskard, DeepChecks, Humanloop, Traceloop/OpenLLMetry, WhyLabs, Maxim AI, LangWatch, PromptLayer, Confident AI, Literal AI, Lunary, Autoblocks, HoneyHive, …) | 0–7 each | rounding to zero |
LangSmith and Langfuse together are 56% of all eval-tool mentions in job postings. If a posting names an eval tool at all, more than half the time it's one of those two. In blog and news coverage the picture is much flatter — LangSmith's lead shrinks to about 20%, with Arize/Phoenix, Langfuse, promptfoo, RAGAS and DeepEval all in play, plus a long tail of a dozen-plus vendors that show up in articles and never appear in hiring at all. The vendor ecosystem is far bigger than the hiring market reflects.
(*Braintrust is noisy — about 20% of its job-posting mentions aren't in an LLM context. And note what's not in that table: MLflow shows up in 2,438 postings and Weights & Biases in ~100, but those are experiment-tracking platforms with an eval helper bolted on, not dedicated eval frameworks. Within AI-eval postings, MLflow appears in 4.7% — i.e. when a team says "we evaluate LLMs and we have a platform," the platform is often the one they already had.)
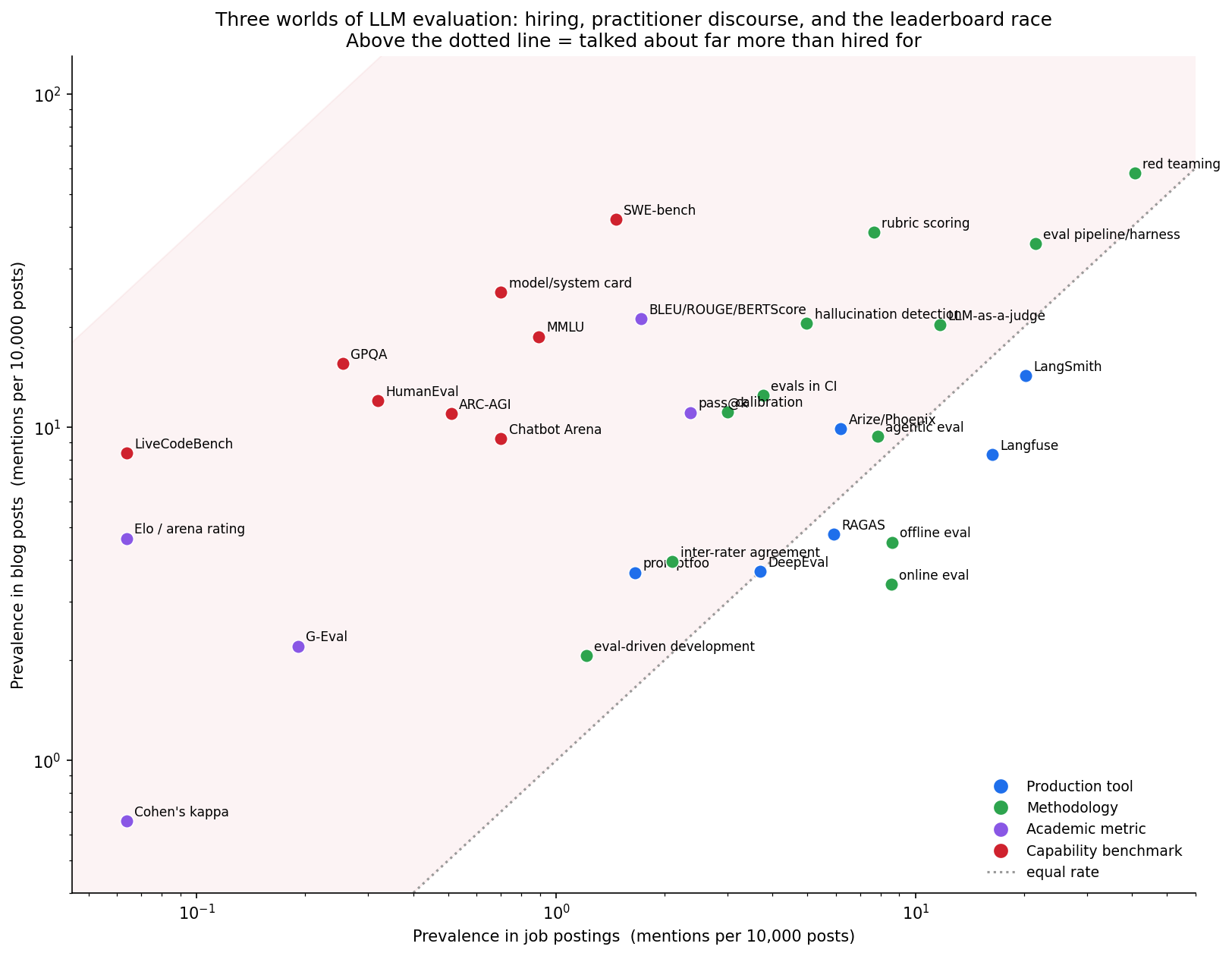
Three worlds that barely touch
Plot each concept by how often it appears in job postings versus blog posts. Anything well above the diagonal is talked about far more than it's hired for.
Production tools (blue) sit near or below the line — LangSmith and Langfuse are actually mentioned more per job posting than per blog post, the signature of something that's entered the hiring stack rather than just the conversation. Capability benchmarks (red) pile up in the top-left corner: heavy in media, absent from hiring. Methodology terms (green) spread across the middle. The academic metrics (purple) — Cohen's kappa, Elo ratings, G-Eval — sit low everywhere and, where they exist, lean to research.
The industry agreed on a method, not a product
We searched the whole methodology vocabulary — rubrics, calibration, inter-rater agreement (Cohen's, Fleiss', Krippendorff's kappa), golden datasets, online vs offline eval, human eval, preference data / Elo, regression testing, evals-in-CI, eval-driven development, red teaming, hallucination / faithfulness, the RAGAS metric quartet, BLEU/ROUGE/BERTScore/G-Eval, pass@k, agentic / trajectory eval, model cards. Highlights:
| Methodology / concept | Jobs | Blog | Scholarly |
|---|---|---|---|
| LLM-as-a-judge | 183 | 709 | 231 |
| rubric / rubric-based scoring | 120 | 1,346 | 159 |
| offline evaluation | 135 | 158 | 14 |
| online evaluation | 134 | 118 | 13 |
| evals wired into CI / CD | 59 | 436 | 8 |
| eval pipeline / harness / framework | 338 | 1,245 | 467 |
| agentic / tool-use evaluation | 153 | 376 | 70 |
| hallucination detection | 78 | 717 | 76 |
| eval-driven development (as a coined term) | 19 | 72 | 0 |
| inter-annotator / inter-rater agreement | 33 | 138 | 62 |
| Cohen's kappa | 1 | 23 | 24 |
| Fleiss' kappa | 0 | 11 | 14 |
| Krippendorff's alpha | 0 | 10 | 4 |
| expected calibration error (ECE) | 0 | 21 | 22 |
| Elo / Bradley-Terry / arena rating | 1 | 162 | 28 |
| BLEU / ROUGE / BERTScore | 27 | 740 | 125 |
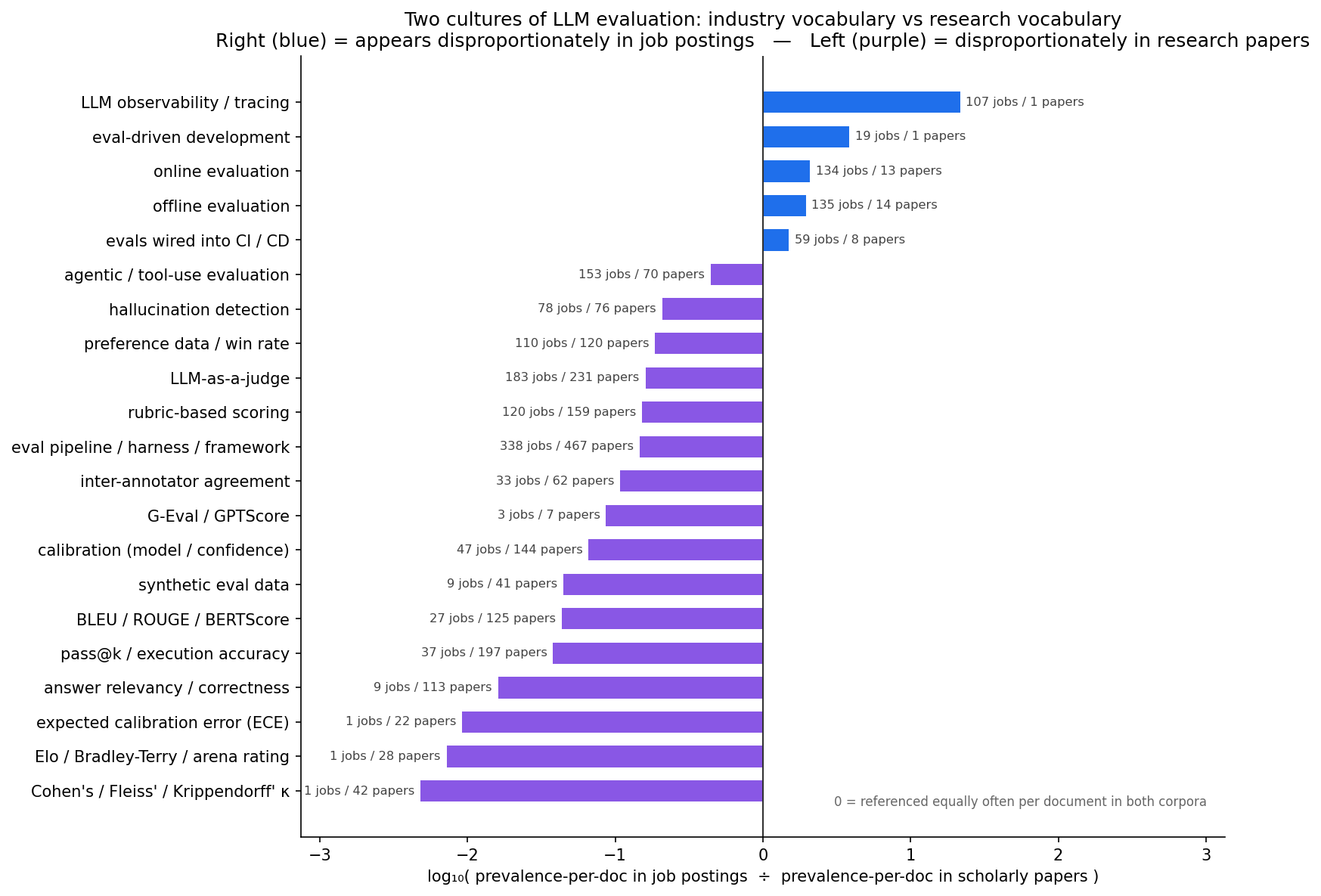
A few things jump out:
- LLM-as-a-judge is the only LLM-native methodology with real hiring traction. It out-mentions every individual product in the blog corpus, and shows up as an explicit line in about 2% of AI-eval job postings. It's "converging," not yet "converged" — but it's the spine of the story.
- The standard form is rubric-based scoring — write a rubric, have an LLM grade against it. "Rubric" appears in 120 postings and 1,346 blog posts; "model-graded eval" is the same idea under another name.
- The offline / online split is real practitioner vocabulary — almost perfectly balanced (135 vs 134 postings), and one of the few methodology distinctions that shows up more in jobs than in research papers.
- The industry bolts LLM eval onto existing software-testing language rather than coining new terms: "evals in CI," "regression suite for prompts," "eval pipeline / harness" (338 postings). "Eval-driven development" as a branded phrase is still small — but it's the obvious next coinage.
- Academic eval rigor didn't transfer. Cohen's kappa: 1 job posting. Fleiss': 0. Krippendorff's: 0. ICC: 0. Expected calibration error: 0. They survive in research papers. Even the informal version — "agreement with human judgment" — is 0 postings. Practitioners ship LLM judges without quantifying judge reliability by any named statistic; researchers don't.
- Classic NLP metrics are becoming a scholarly artifact — BLEU / ROUGE / BERTScore: 27 postings vs 125 papers.
The benchmarks everyone writes about — and nobody hires for
This is the cleanest split in the data.
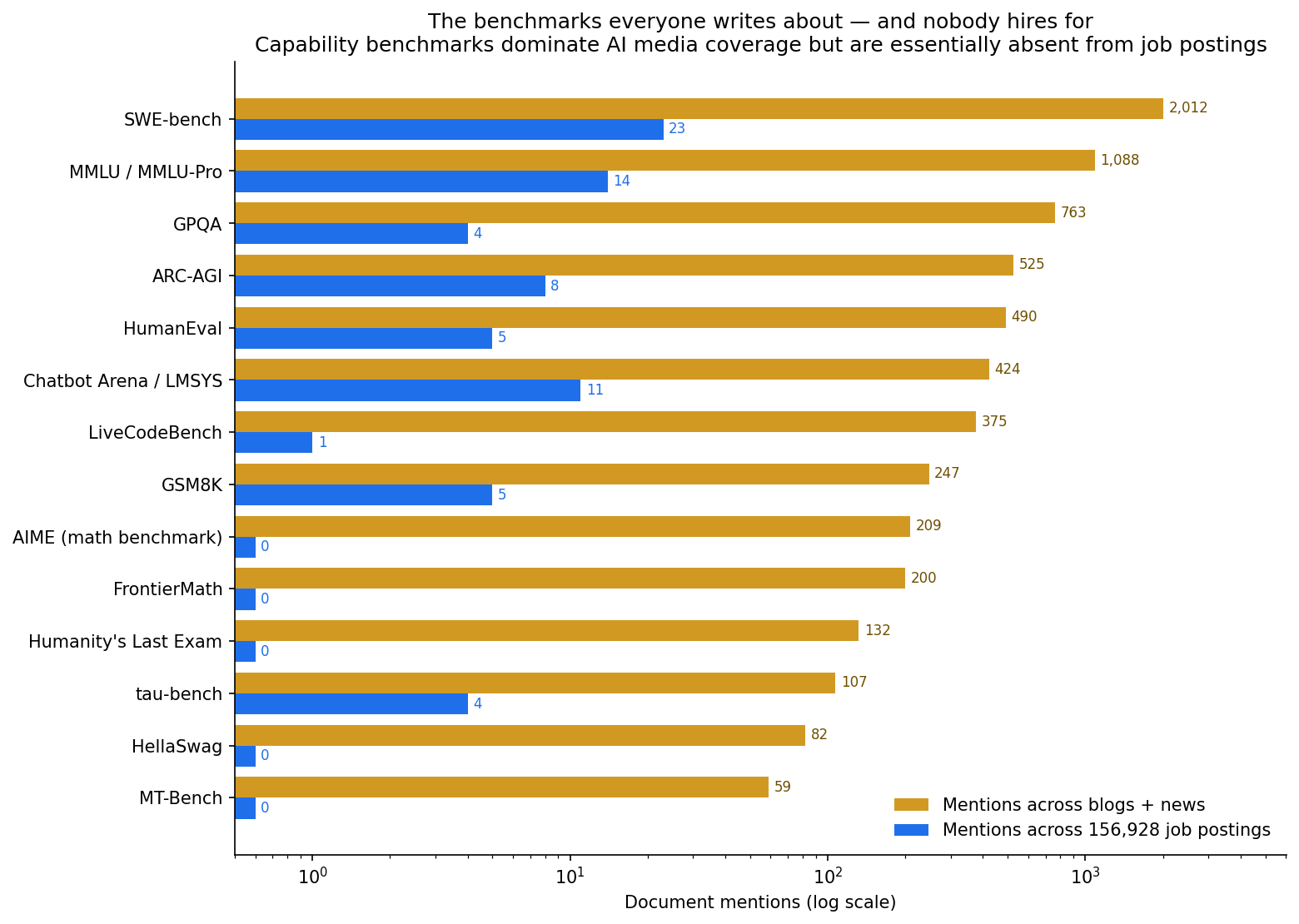
| Benchmark | Blog + news mentions | Job postings |
|---|---|---|
| SWE-bench | 2,012 | 23 |
| MMLU / MMLU-Pro | 1,088 | 14 |
| GPQA | 763 | 4 |
| ARC-AGI | 525 | 8 |
| HumanEval | 490 | 5 |
| Chatbot Arena / LMSYS | 424 | 11 |
| LiveCodeBench | 375 | 1 |
| GSM8K | 247 | 5 |
| AIME · FrontierMath · Humanity's Last Exam | 209 / 200 / 132 | 0 / 0 / 0 |
The leaderboard apparatus that dominates every model-release announcement is basically not part of how companies describe the eval work they're hiring for — and that actually makes sense. Those benchmarks measure model capability, a lab and research concern. A company hiring an AI Engineer cares about product eval: does our RAG system answer correctly on our data, within our latency budget. That's the LangSmith / Langfuse / RAGAS / LLM-as-a-judge layer. But the gap is three orders of magnitude wide, so it's worth saying out loud: the benchmark in this week's model launch is not on the job description.
"LLM eval tooling" is, concretely, an AI Engineer job
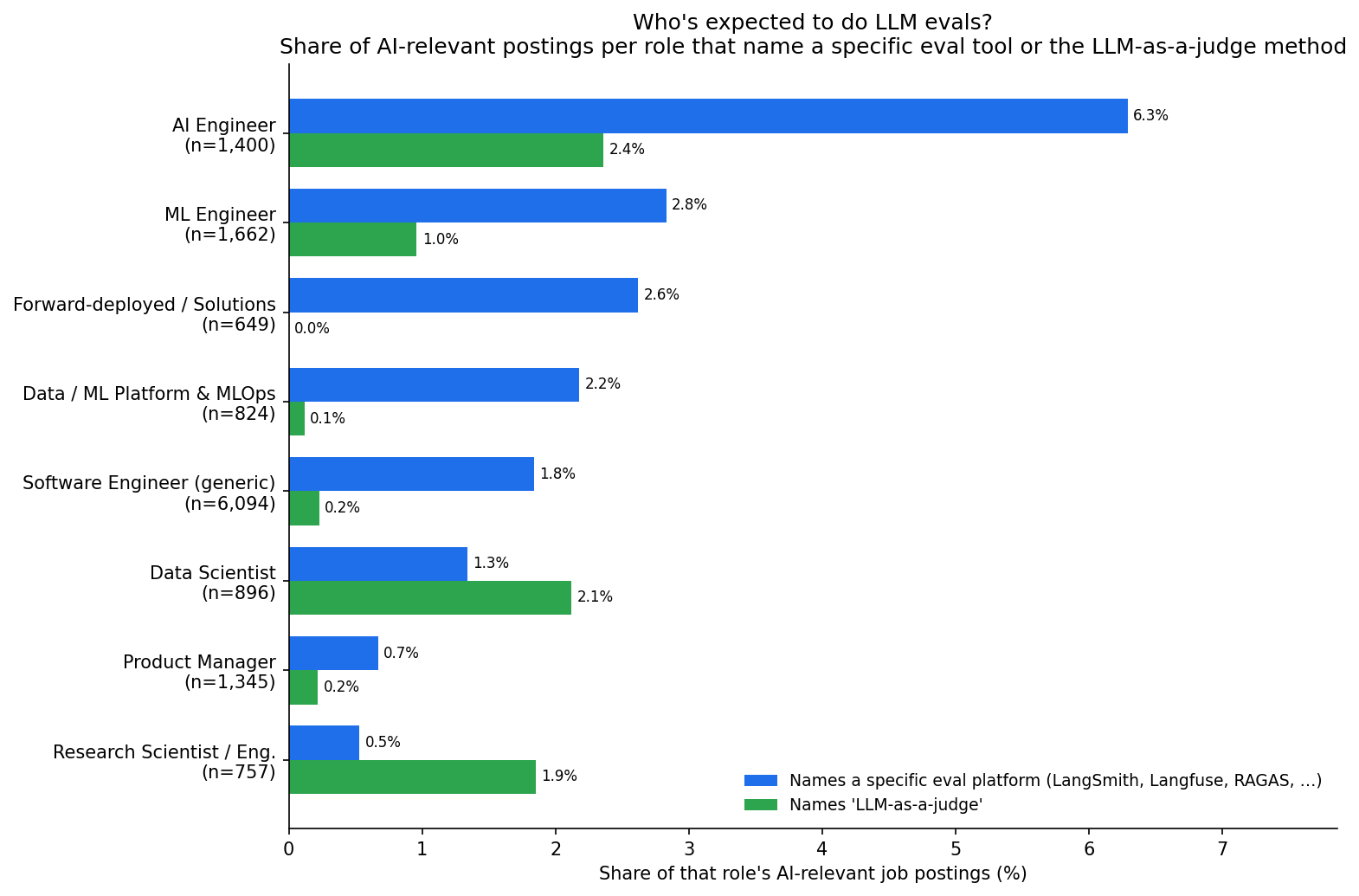
Within AI-relevant postings (those mentioning an LLM or GenAI term), by role family:
| Role | AI-relevant postings | Names a specific eval platform | Names "LLM-as-a-judge" |
|---|---|---|---|
| AI Engineer | 1,400 | 6.3% | 2.4% |
| ML Engineer | 1,662 | 2.8% | 1.0% |
| Forward-deployed / Solutions | 649 | 2.6% | 0.0% |
| Data / ML Platform & MLOps | 824 | 2.2% | 0.1% |
| Software Engineer (generic) | 6,094 | 1.8% | 0.2% |
| Data Scientist | 896 | 1.3% | 2.1% |
| Product Manager | 1,345 | 0.7% | 0.2% |
| Research Scientist / Engineer | 757 | 0.5% | 1.9% |
- AI Engineer postings name a specific eval platform at 2–3× the rate of any other role. If you want to do this work, that's the title to look for. (We've broken down what separates AI Engineer from ML Engineer and Data Scientist before — eval ownership is one more thing that lands on the AI-Engineer side.)
- Research Scientists evaluate heavily but in a parallel universe — 52% of their postings mention evaluation, but only 0.5% name a commercial platform. They use research benchmarks and write their own harnesses; the SaaS eval market mostly isn't talking to them.
- MLOps / Platform engineers barely touch LLM eval — the lowest of any engineering role — and when they do, they lean Langfuse over LangSmith. Self-hosted observability fits the infra crowd.
- By seniority, naming a specific eval platform peaks at senior and staff; naming LLM-as-a-judge peaks at principal. It reads as a "you own the eval strategy" signal, not an entry-level checkbox.
What this means for you
If you're upskilling or hiring for LLM eval: learn an LLM-as-a-judge workflow — rubric design, judge prompting, calibrating the judge against a small human-labeled set — get hands-on with one tracing/eval platform (LangSmith or Langfuse together cover more than half the market), and add RAGAS if you touch RAG. Skip memorizing the leaderboard du jour; the people paying for eval work aren't asking about it.
If you're an AI Engineer: this is squarely your job. Eval ownership is showing up in senior, staff, and principal AI-Engineer reqs more than anywhere else.
If you're choosing an eval stack: the market hasn't standardized on a framework, so don't over-index on tool choice. It has standardized on a method. Build the LLM-as-a-judge + rubric + offline/online + CI loop first; the tool is the easy part to swap.
If you're a Research Scientist: you already do this — but you're using a vocabulary (kappa stats, ECE, Elo, BLEU/ROUGE) that essentially no product team uses. Worth knowing the translation layer when you talk to one.
Methodology
Counts are document counts, de-duplicated per document, from phrase matching on the full text of each posting/article/paper in the Skillenai enriched indices, snapshot 2026-05-12. Multi-spelling concepts are OR-groups of phrases. Phrase prevalence is a signal, not a strict requirement — a posting that names "LangSmith" might list it as nice-to-have or simply describe the team's stack. We excluded or caveated noisy tokens: "perplexity" is overwhelmingly the company Perplexity AI, not the metric; "guardrails" is about 58% the plain English word; "A/B testing" is overwhelmingly product/marketing; the jobs index spans roughly March–May 2026 so there's no time trend; and Big Tech (Google, Apple, Microsoft, NVIDIA) is mostly absent because they use proprietary ATS platforms we don't crawl. Full tables, the role and seniority cross-tabs, and the reproducible figure code are in the skillenai-notebooks repo.