AI Engineers Wire APIs. ML Engineers Fine-Tune the Model.
For the last two years, the dominant story about AI Engineers has been that the job is mostly API plumbing — wire up an LLM, add RAG, ship the product. But there's a counter-narrative gaining traction: fine-tuning is making a comeback, and AI Engineers are the ones it's coming back for.
We pulled 6,802 job postings from the Skillenai index — 2,795 Data Scientist, 2,893 ML Engineer, and 1,114 AI Engineer roles posted between March and early May 2026 — to test that claim. The cross-section is striking. The time series isn't. And the most interesting finding is that "fine-tuning" turns out to mean two completely different things depending on which role posts the job.
Get an email when we publish a new post. No account needed, unsubscribe anytime.
The Headline: AI Engineers Mention Fine-Tuning Most
Across all 6,802 postings, fine-tuning prevalence by role looks like this:
| Role | Postings | % mentioning fine-tuning | 95% CI |
|---|---|---|---|
| Data Scientist | 2,795 | 4.9% | 4.1% – 5.8% |
| ML Engineer | 2,893 | 18.2% | 16.8% – 19.6% |
| AI Engineer | 1,114 | 26.2% | 23.7% – 28.9% |
An AI Engineer posting is more than five times more likely to mention fine-tuning than a Data Scientist posting, and roughly 1.4× more likely than an ML Engineer posting. All three pairwise gaps are highly significant (chi-square p < 1e-7 across the board, Cramér's V = 0.23). On the surface, the "fine-tuning is for AI Engineers" narrative looks correct.
Then You Look at What "Fine-Tuning" Actually Means
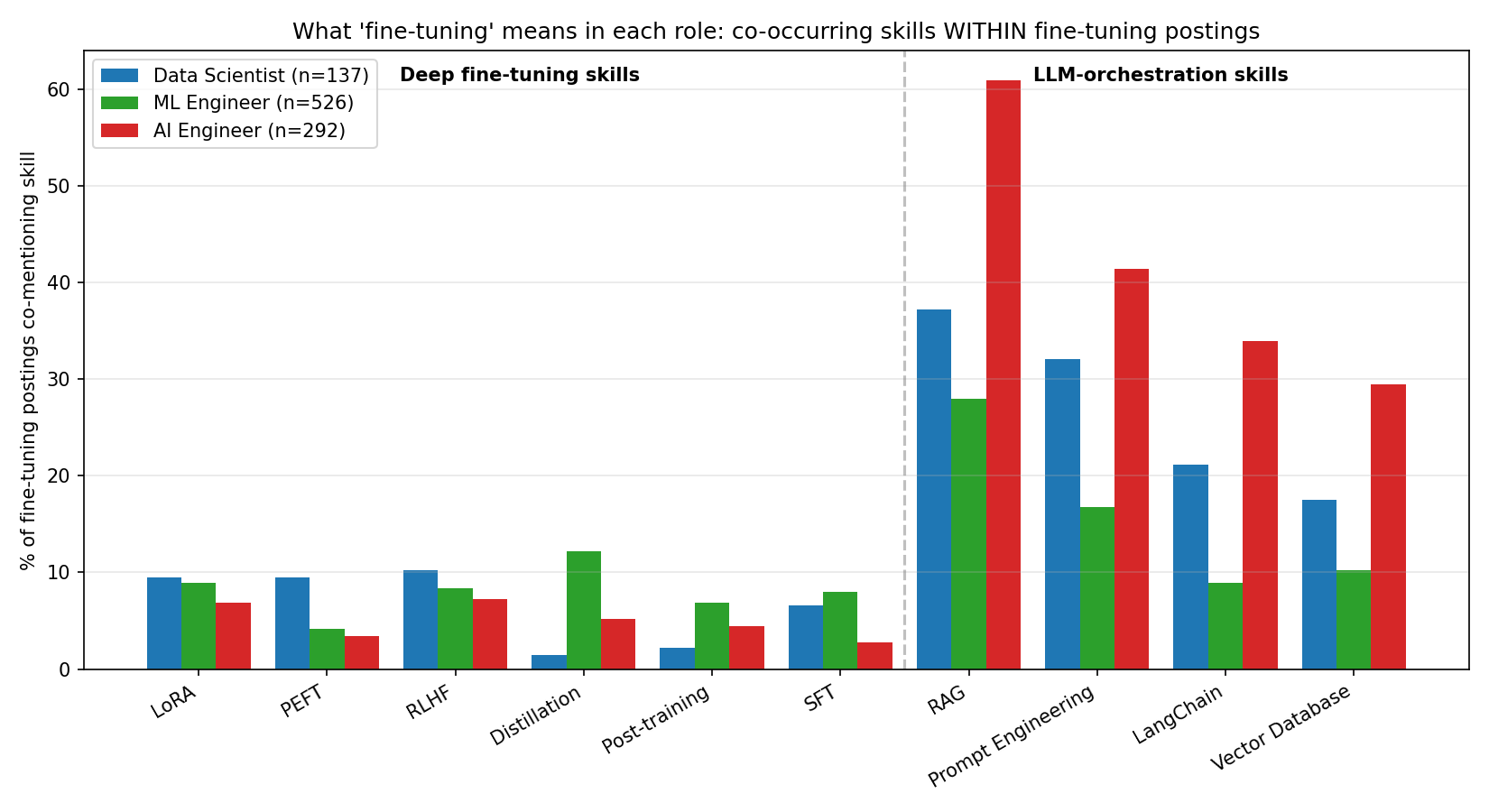
Inside each role, we counted how often a fine-tuning posting also mentioned ten adjacent skills, split into two clusters:
- Deep fine-tuning skills: LoRA, PEFT, RLHF, distillation, post-training, supervised fine-tuning (SFT)
- LLM-orchestration skills: RAG, prompt engineering, LangChain, vector databases
| Skill | DS (n=137) | MLE (n=526) | AIE (n=292) |
|---|---|---|---|
| Deep fine-tuning skills | |||
| LoRA | 9.5% | 8.9% | 6.8% |
| PEFT | 9.5% | 4.2% | 3.4% |
| RLHF | 10.2% | 8.4% | 7.2% |
| Distillation | 1.5% | 12.2% | 5.1% |
| Post-training | 2.2% | 6.8% | 4.5% |
| SFT | 6.6% | 8.0% | 2.7% |
| LLM-orchestration skills | |||
| RAG | 37.2% | 27.9% | 61.0% |
| Prompt engineering | 32.1% | 16.7% | 41.4% |
| LangChain | 21.2% | 8.9% | 33.9% |
| Vector database | 17.5% | 10.3% | 29.5% |
Read the AI Engineer column: every single deep fine-tuning skill is lower in AI Engineer postings than in ML Engineer postings. Distillation is more than twice as common in MLE fine-tuning postings (12.2%) as in AIE (5.1%). SFT is three times as common.
Now read the orchestration cluster: 61% of AI Engineer fine-tuning postings also mention RAG. 34% mention LangChain. 30% mention vector databases. These rates are 2–4× the ML Engineer rates.
The pattern is unmistakable. When an AI Engineer posting says "fine-tuning," it almost always says it as one item on a long list dominated by RAG, prompt engineering, LangChain, and vector databases. When an ML Engineer posting says "fine-tuning," it's far more likely to be paired with the actual technical machinery of fine-tuning — distillation pipelines, post-training, LoRA, RLHF.
Two Quotes From Real Postings
The split is even clearer in the prose. From an AI Engineer job description (NeuBird.ai):
"You will work with RLHF and fine-tuning of LLMs. This role requires a blend of analytical skills, creativity, and strong AI domain knowledge."
Note the framing: fine-tuning sits next to "creativity" and "AI domain knowledge." It's a competency to mention, not the core of the job.
From an ML Engineer job description at AMD:
"You have experience building and operating end-to-end ML pipelines for training, fine-tuning, reinforcement learning, and agentic systems."
Or even more starkly, a posting at Reflection AI literally titled Forward Deployed Engineer | LLM Post-training:
"Drive model fine-tuning and evaluations for enterprise customers. Run fine-tuning workflows on customer data."
For ML Engineers, fine-tuning is sometimes the entire job. For AI Engineers, it's a checkbox in a list dominated by orchestration.
Did Anything Move in Two Months?
Short answer: not in any way the data can confirm. We ran a Mann-Kendall trend test on the five weeks with at least 100 postings per role:
| Role | Range across 5 weeks | Mann-Kendall p |
|---|---|---|
| Data Scientist | 2.5% – 6.0% | 0.81 |
| ML Engineer | 13.9% – 21.1% | 0.46 |
| AI Engineer | 14.6% – 31.9% | 0.46 |
Eight weeks of data and roughly 150 AI Engineer postings per week is not enough to see a trend — week-to-week noise dwarfs any real movement. The ML Engineer series is the only one with a hint of directional shape, climbing from 13.9% in early April back to 21.1% by late April, but with five points it's a curiosity, not a finding. We'll revisit in Q3 when there's a longer time series.
So Is Fine-Tuning Being Absorbed by MLEs and Data Scientists?
By Data Scientists? Hardly. At 4.9% prevalence, fine-tuning is barely on the DS radar. When it does appear, it tends to be research-flavored — PEFT and LoRA show up at similar rates to MLEs — but the role is still anchored in SQL, statistics, and experimentation, not model surgery.
By ML Engineers? Partially yes — and this is the more interesting answer. The deep technical fine-tuning toolkit lives in MLE postings, not AIE postings:
- Distillation: 12.2% (MLE) vs 5.1% (AIE)
- Post-training: 6.8% (MLE) vs 4.5% (AIE)
- LoRA: 8.9% (MLE) vs 6.8% (AIE)
- RLHF: 8.4% (MLE) vs 7.2% (AIE)
If "fine-tuning is being absorbed by other roles" means the actual training-pipeline work — distillation, RLHF, post-training, LoRA — is concentrated in ML Engineer postings rather than AI Engineer postings, then yes. AI Engineers have the word "fine-tuning" more often. ML Engineers have the substance of it.
What This Means For Your Career
If you're an AI Engineer and you want fine-tuning to mean something more than "I called the OpenAI fine-tuning API once": treat the orchestration co-mentions as a warning. The role is shaped around RAG and LangChain, not LoRA and post-training. To deepen, you need to seek out postings that actually pair fine-tuning with distillation, post-training, or RLHF — and most of those postings carry the title "ML Engineer," not "AI Engineer."
If you're an ML Engineer: fine-tuning prevalence in your role is solidly in the high teens and the deep technical signal is concentrated here. Distillation, RLHF, and post-training are MLE differentiators in 2026. If you're hiring for a role that needs hands-on training-pipeline work, "ML Engineer" is the title that selects for it; "AI Engineer" is not.
If you're a Data Scientist: fine-tuning isn't expected of most DS roles, but the small slice of DS postings that do mention it tend to be the most methodologically deep — PEFT, supervised fine-tuning, preference alignment. If that's where your interest lies, target healthcare LLMs, recommendation systems research, and ML-research-flavored DS roles.
The cleanest one-line summary: AI Engineers fine-tune the API. ML Engineers fine-tune the model.
Methodology
Job postings pulled from the Skillenai prod-enriched-jobs index (8 weeks, 2026-03-10 → 2026-05-03). Roles identified by exact match on the parsed role field, with aliases collapsed for ML Engineer (ML Engineer + Machine Learning Engineer) and AI Engineer (AI Engineer + Artificial Intelligence Engineer). Fine-tuning prevalence measured by phrase match across fine-tuning, fine tuning, finetuning, fine-tune, finetune on the posting text. Statistical tests: chi-square contingency for cross-section, Mann-Kendall on weekly proportions for trend, Wilson score intervals for 95% CIs. Big Tech employers (Google, Apple, Microsoft, NVIDIA, Netflix) are under-represented because their proprietary ATS platforms are not scraped — this likely under-states the deep fine-tuning signal in MLE postings, supporting rather than threatening the headline finding. Full data and reproduction code: skillenai-notebooks/fine-tuning-by-role.