Tech blogs write about LLMs too much. Job postings hire for these other skills instead.
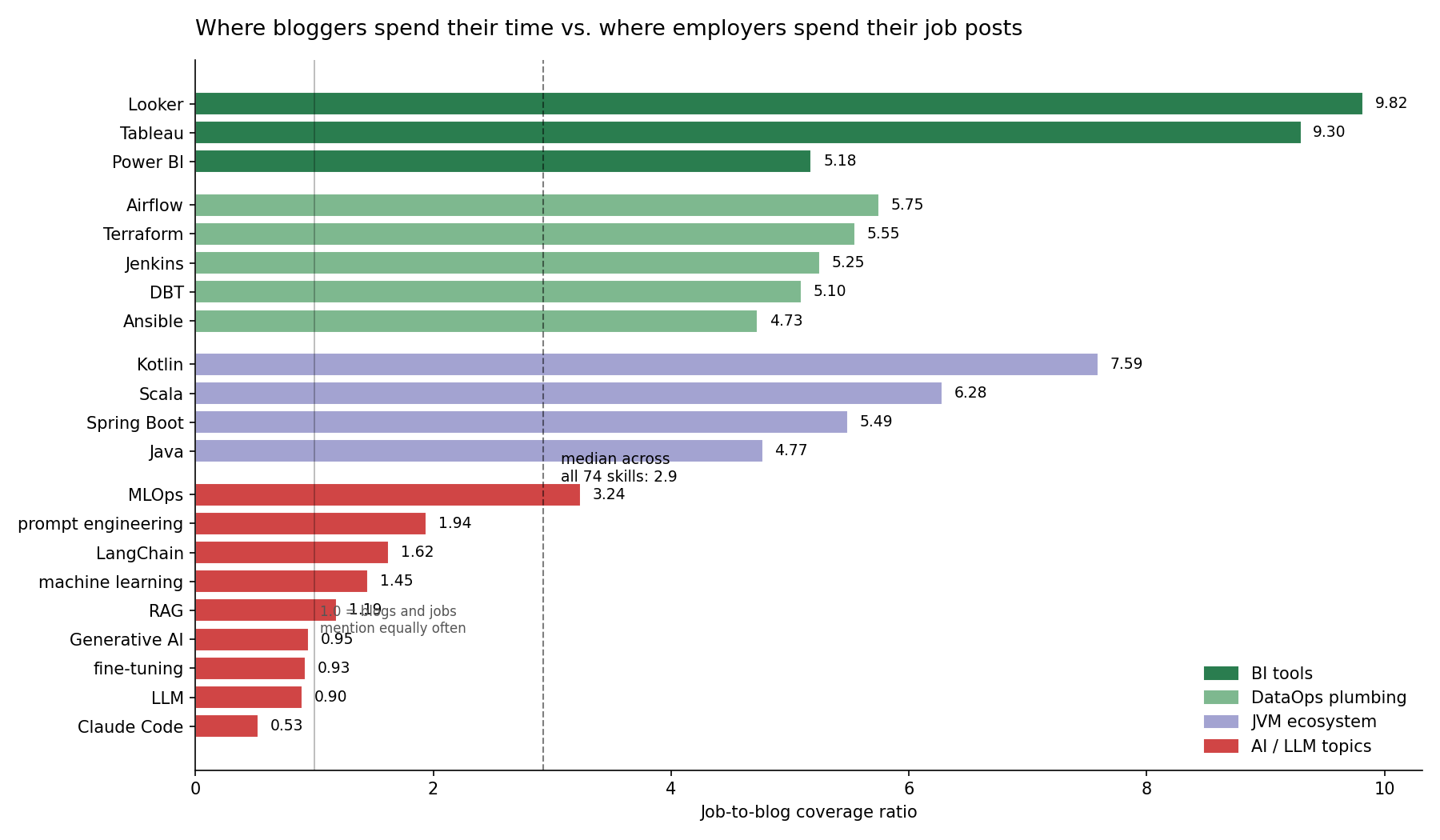
Tech bloggers are writing about Claude Code at almost 2x the rate jobs ask for it. Employers are hiring for Looker at 10x the rate anyone is writing about it.
We ranked 74 popular tech skills by the ratio of how often a job posting mentions them to how often a blog post mentions them, across 205,895 enriched job postings and 408,420 enriched blog posts on the Skillenai indices. The picture is unambiguous: tutorial writers chase novelty, employers buy durability, and the gap shows up at 5-10x.
## The 12 skills employers are begging for that no one is writing about
| Rank | Skill | Jobs | Blog posts | Job:blog ratio |
|---|---|---|---|---|
| 1 | Looker | 5,215 | 1,053 | 9.82 |
| 2 | Tableau | 7,904 | 1,686 | 9.30 |
| 3 | Kotlin | 5,481 | 1,432 | 7.59 |
| 4 | GCP | 22,111 | 6,067 | 7.23 |
| 5 | Scala | 3,846 | 1,214 | 6.28 |
| 6 | Airflow | 5,207 | 1,797 | 5.75 |
| 7 | Redux | 2,309 | 822 | 5.57 |
| 8 | Terraform | 15,657 | 5,600 | 5.55 |
| 9 | Spring Boot | 3,122 | 1,129 | 5.49 |
| 10 | Jenkins | 6,694 | 2,528 | 5.25 |
| 11 | Power BI | 4,979 | 1,906 | 5.18 |
| 12 | DBT | 4,707 | 1,832 | 5.10 |
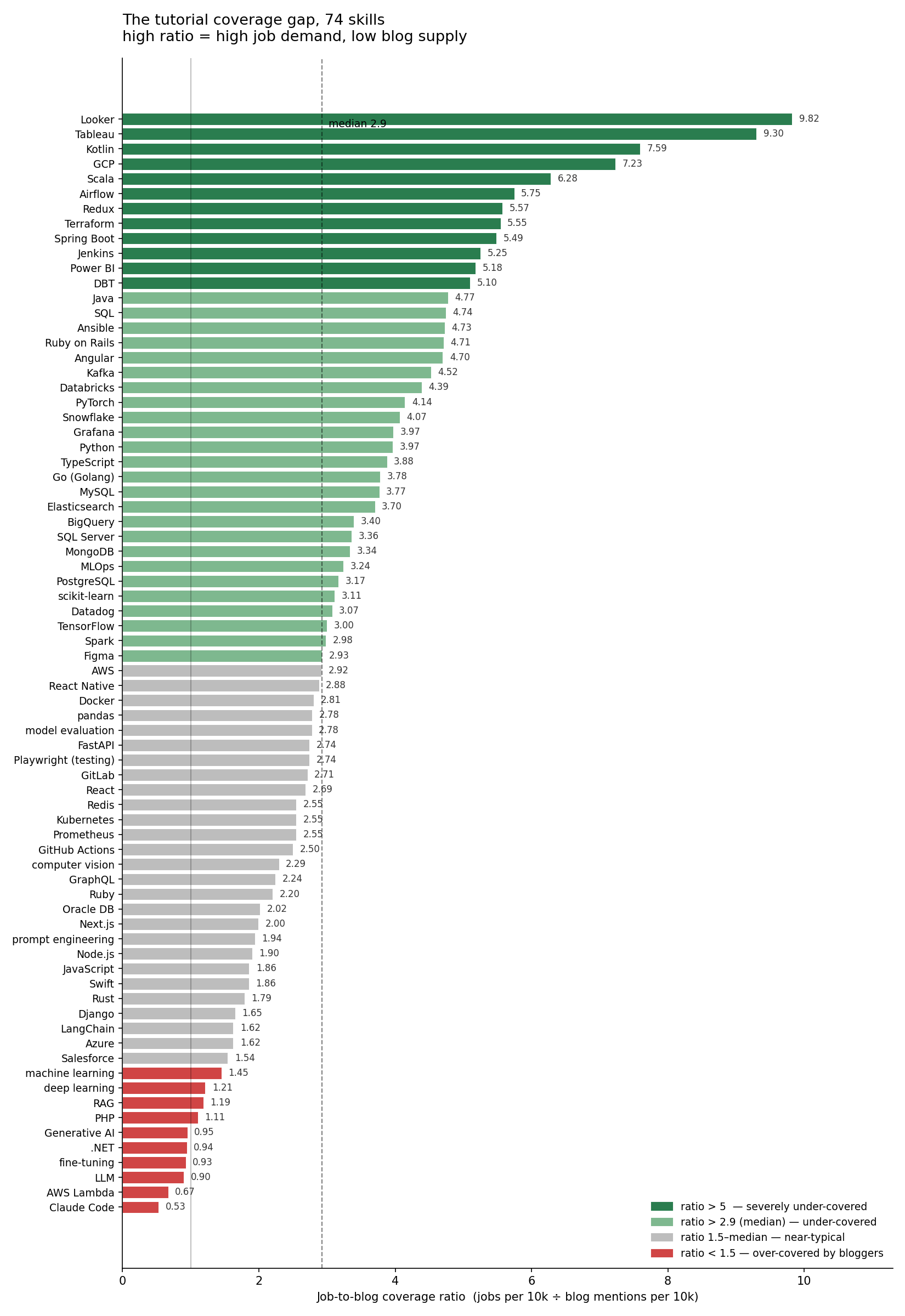
The median skill in our sample has a job-to-blog ratio of \~2.9. Anything above \~5 is meaningfully under-blogged. The pattern is clean: three clusters explain the entire under-served list.
- Business Intelligence tools — Looker, Tableau, Power BI. Three of the top eleven. The dashboards employers actually use to run their businesses.
- DataOps plumbing — Airflow, Terraform, Jenkins, DBT, Ansible. Five of the top fifteen. The pipeline glue that makes the modern data stack work.
- JVM ecosystem — Kotlin, Scala, Spring Boot, Java. Four of the top fifteen. The languages large enterprises still build on.
Get an email when we publish a new post. No account needed, unsubscribe anytime.
And the 12 skills with way too many tutorials and not enough jobs
| Rank | Skill | Jobs | Blog posts | Job:blog ratio |
|---|---|---|---|---|
| 1 | Claude Code | 4,336 | 16,296 | 0.53 |
| 2 | AWS Lambda | 952 | 2,819 | 0.67 |
| 3 | LLM | 16,389 | 36,125 | 0.90 |
| 4 | fine-tuning | 4,073 | 8,696 | 0.93 |
| 5 | .NET | 7,375 | 15,515 | 0.94 |
| 6 | Generative AI | 12,087 | 25,149 | 0.95 |
| 7 | PHP | 2,122 | 3,801 | 1.11 |
| 8 | RAG | 6,619 | 11,052 | 1.19 |
| 9 | deep learning | 4,810 | 7,864 | 1.21 |
| 10 | machine learning | 24,850 | 33,996 | 1.45 |
| 11 | Salesforce | 6,405 | 8,230 | 1.54 |
| 12 | Azure | 2,787 | 3,404 | 1.62 |
One cluster explains almost all of the over-served list: the AI/LLM stack. Every member — Claude Code, LLM, RAG, fine-tuning, Generative AI — sits below median, and the top of the cluster sits below the equal-coverage line. The tech blogosphere is over-indexed on the entire AI/LLM stack relative to actual hiring.
Seen on a chart
The entire 74-skill ranking looks like this. Green = under-served. Red = over-served. The dashed line is the median.
 Or, on a log-log plot of job demand vs blog supply:
Or, on a log-log plot of job demand vs blog supply:
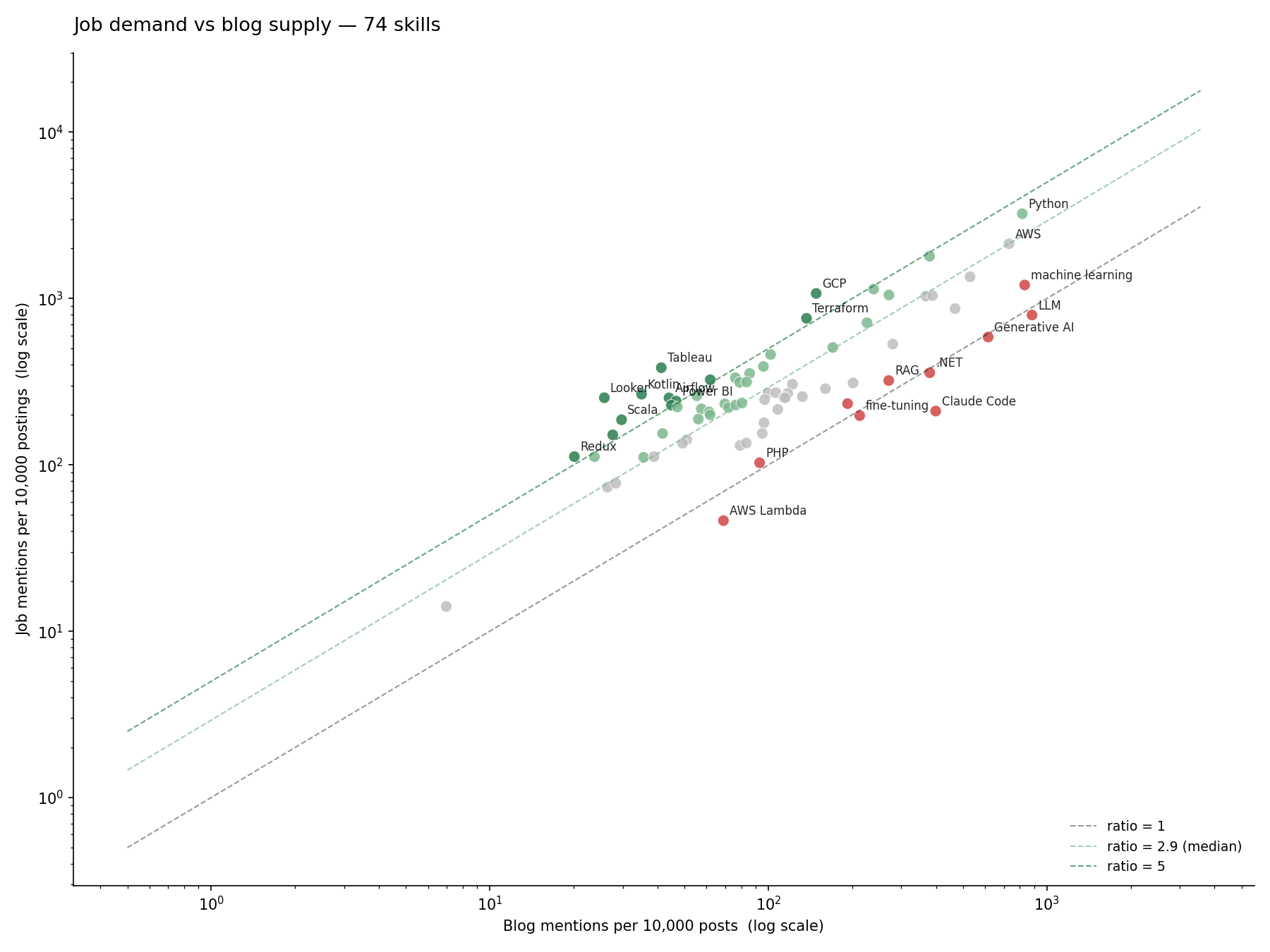 Every red dot — the AI/LLM cluster — sits below the median diagonal. Every green dot — BI, DataOps, JVM — sits above it. Python and AWS straddle the median because both populations care about them.
Every red dot — the AI/LLM cluster — sits below the median diagonal. Every green dot — BI, DataOps, JVM — sits above it. Python and AWS straddle the median because both populations care about them.
Who is actually writing the missing tutorials?
For each of the twelve most under-served skills, we aggregated blog posts by author. Standard hygiene applied: no team accounts, no email-as-byline, no domain-as-author, no Slashdot bots, no multi-author blobs, and a 333-domain denylist for the synthetic-persona content-farm network we identified earlier this year.
A few names dominate.
| Author | Site | Skills covered (of 12) | Total posts | Max per-skill authority |
|---|---|---|---|---|
| Tobias Macey | dataengineeringpodcast.com | 11 | 634 | 1.56 |
| Alex Merced | datalakehousehub.com / iceberglakehouse.com | 8 | 527 | 2.79 |
| Rahul | aicodereview.cc | 8 | 315 | 0.75 |
| Julien GOURMELEN | wizops.fr | 5 | 355 | 1.41 |
| Andreas & Michael Wittig | cloudonaut.io | 4 | 72 | 3.02 |
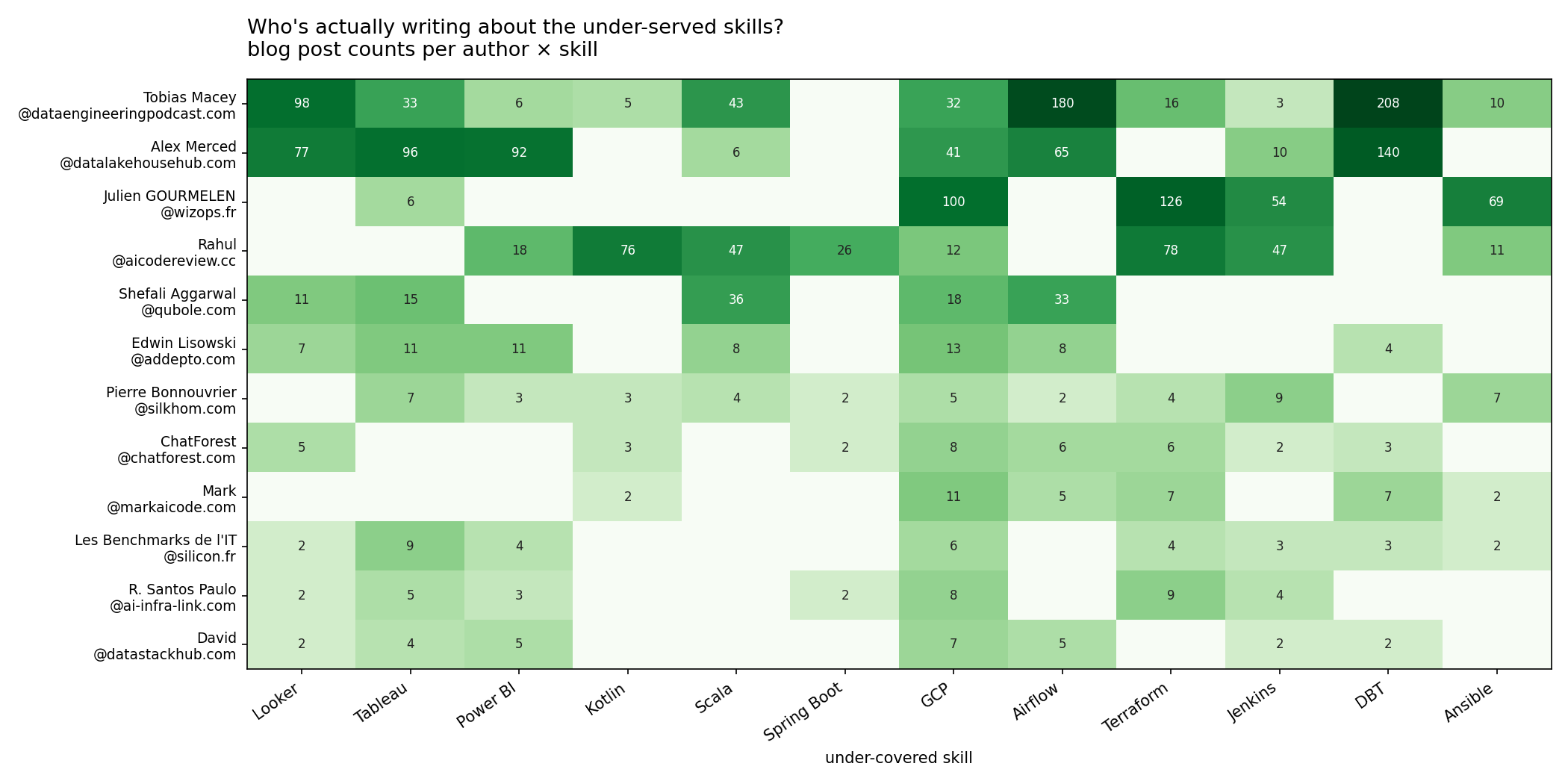 Two names stand out.
Two names stand out.
Tobias Macey runs the Data Engineering Podcast. He's the only writer in our corpus who covers eleven of the twelve most-under-blogged skills. His catalogue of interviews — 208 episodes touching DBT, 180 touching Airflow, 98 touching Looker, 43 touching Scala — is, by simple count, the de facto data-engineering reference on the open web. (We treat each podcast episode as a blog post because that's how it lands in our crawl.)
Alex Merced is the highest-authority multi-topic gap-filler. He writes from inside the lakehouse-vendor world (Dremio, Iceberg) and his per-post authority sits at 2.79, comfortably above the corpus median.
Andreas & Michael Wittig (cloudonaut.io) post the most authoritative content in the Terraform / Jenkins corner.
For most of the individual under-served skills, the top authors by volume are vendor SEO content — Mary Rybalchenko at windsor.ai, Shefali Aggarwal at qubole.com, Edwin Lisowski at addepto.com. There is, in 2026, no independent named tutorial creator with significant volume writing about Looker, Tableau, or Power BI.
Why the gap exists
A tutorial economy is, structurally, an attention economy. Writers write what generates social signal — new tools, frontier models, the freshest demo. RAG, Claude Code, fine-tuning, and LLMs are interesting. They produce screenshots that get retweeted. Looker dashboards do not.
Employers, on the other hand, hire for what they need to operate the business: a dashboard tool to read the data, a pipeline tool to land the data, and a JVM service to keep the legacy core running while everyone argues about the rewrite.
The result, this quarter, is a measurable gap between what the open web teaches and what employers pay for. That gap is concentrated in three skill clusters and, by simple author-count, is being filled by two people: a podcaster and a lakehouse advocate.
What it means for your career
If you're job-hunting: the durable skills aren't the ones lighting up your feed. Looker, Tableau, Power BI, Airflow, Terraform, DBT, Kotlin, Spring Boot — these are the skills that get past the first resume screen at scale. The tutorial supply is thinner than the demand, which means learning them is harder than learning RAG, but standing out with them is much easier.
If you write technical content: the most lucrative tutorial niche on the internet right now is the one no influencer wants. A solid Looker series, a real Airflow course, an honest set of Kotlin tutorials — these don't go viral, but they get bookmarked, linked, and quietly relied on by working engineers for years. Search visibility is also less competitive: ranking for "how to write a Tableau parameter action" is a much shorter fight than ranking for "how to build a RAG system."
If you're building courses or training programs: the LLM bootcamp market is saturated. The BI bootcamp market, at the size we're seeing here, is not.
Methodology
For each of 74 candidate skills, we counted job postings and blog posts whose extractedText contains the skill phrase (any of a small OR-group of spellings to handle variant casing and acronym expansion). We then computed job-mentions-per-10,000-postings and blog-mentions-per-10,000-posts. The ratio of the two is the coverage gap.
- Jobs index (
prod-enriched-jobs): 205,895 documents, ingested from 2026-03-10 onward. - Blog index (
prod-enriched-blog): 408,420 documents after removing a 333-domain coordinated content-farm network identified earlier this year and five known ATS / medical / preprint domains that get mis-classified as blogs. - Author filter (for the gap-filler section): no team accounts, no email-as-byline, no domain-as-author, no Slashdot-style bot bylines, no multi-author blobs, no PBN-domain bylines.
- Concepts dropped for analyzer artifacts:
C++,C#,Excel,Bash,R,Cursor— their phrase tokens collide with English text or other tokens after analysis. For ambiguous tokens that survived (pandas,Playwright,Go) we required a co-occurring disambiguator phrase. - Caveat: a blog mention is not the same as a tutorial. A post that contains the word "Looker" might or might not teach Looker. A job posting that lists Looker almost certainly requires it. The ratio is biased in the same direction for every skill (jobs are stricter than blogs), but the magnitude may vary across skills.
- Caveat: the candidate skill list comes from the jobs index, so skills heavily blogged but rare in job postings (game-dev frameworks, niche scientific stacks) are by construction not in the table.
- Caveat: Big Tech is under-represented in our jobs corpus — Google, Apple, Microsoft, NVIDIA, and Netflix mostly run proprietary ATS platforms we don't crawl, which may suppress GCP / .NET / Azure / Swift demand.
Full methodology, raw counts, and all scripts to reproduce: skillenai-notebooks/tutorial-coverage-gap.