AI Engineer Is the Longest Jump From Data Scientist (Skill-Stack Map)
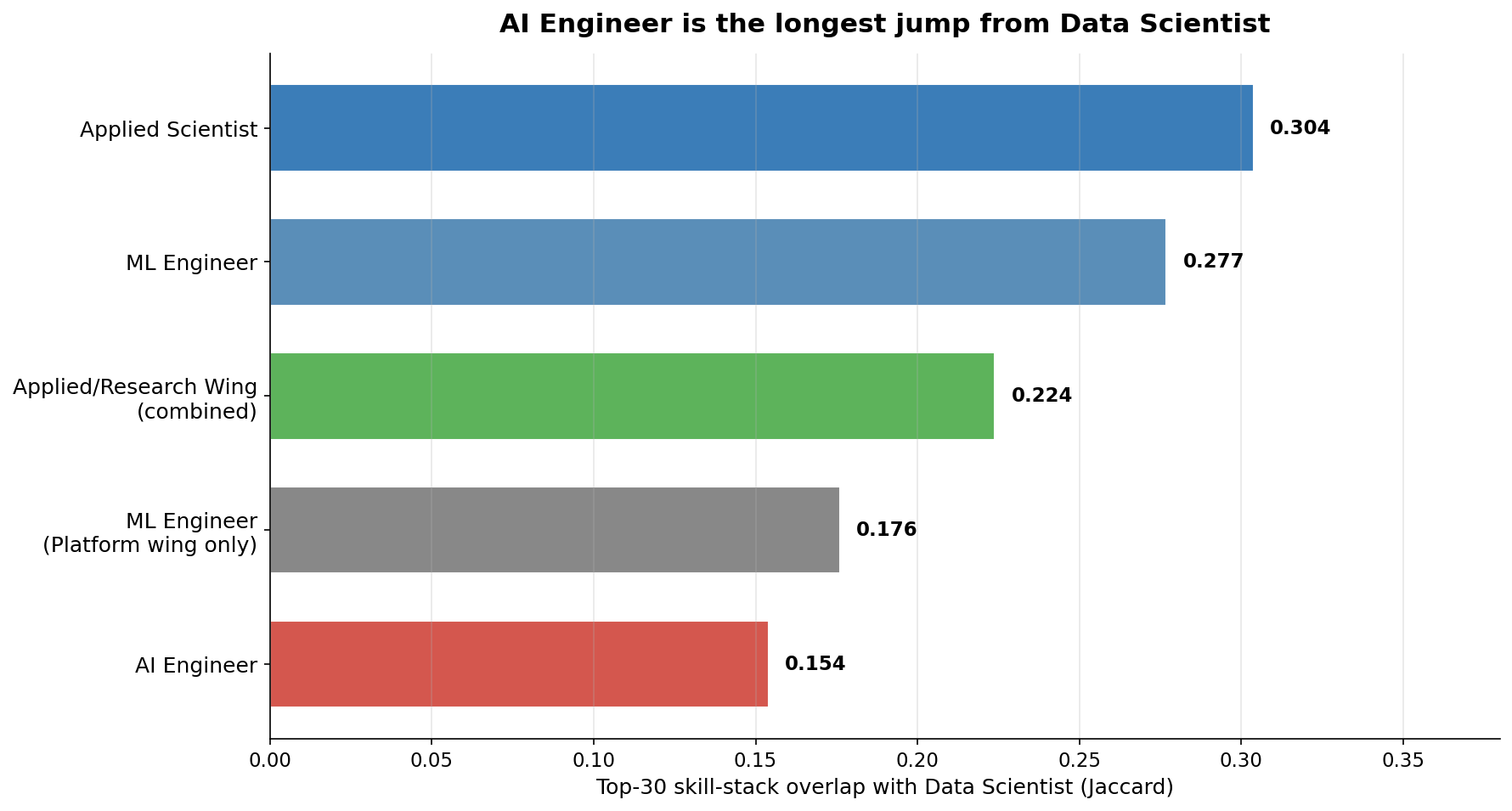
The most-discussed career move in AI hiring is Data Scientist to AI Engineer. Measured by skill-stack overlap across thousands of job postings, that is the longest jump on the board — not the shortest.
We pulled the skills required by Data Scientist, ML Engineer, AI Engineer, Applied Scientist, Research Scientist, Research Engineer, and Applied AI Engineer postings, and measured how much each role's skill stack overlaps with Data Scientist's.
The order is the opposite of the popular narrative.
## Where Data Scientists actually have the shortest jump
Top-30 skill overlap with Data Scientist (Jaccard, threshold ≥5% prevalence):
| Target role | n_jobs | Jaccard | Skills to learn |
|---|---|---|---|
| Applied Scientist (excluding Amazon) | 156 | 0.333 | 15 |
| Applied Scientist (all) | 281 | 0.304 | 16 |
| ML Engineer | 3,049 | 0.277 | 17 |
| Applied / Research Wing (combined) | 1,000 | 0.224 | 19 |
| ML Engineer — Applied/Research/Training/Foundation | 189 | 0.224 | 19 |
| ML Engineer — Platform/Infra/Inference | 137 | 0.176 | 21 |
| AI Engineer | 1,182 | 0.154 | 22 |
| Research Engineer | 515 | 0.132 | 23 |
| Applied AI Engineer | 322 | 0.132 | 23 |
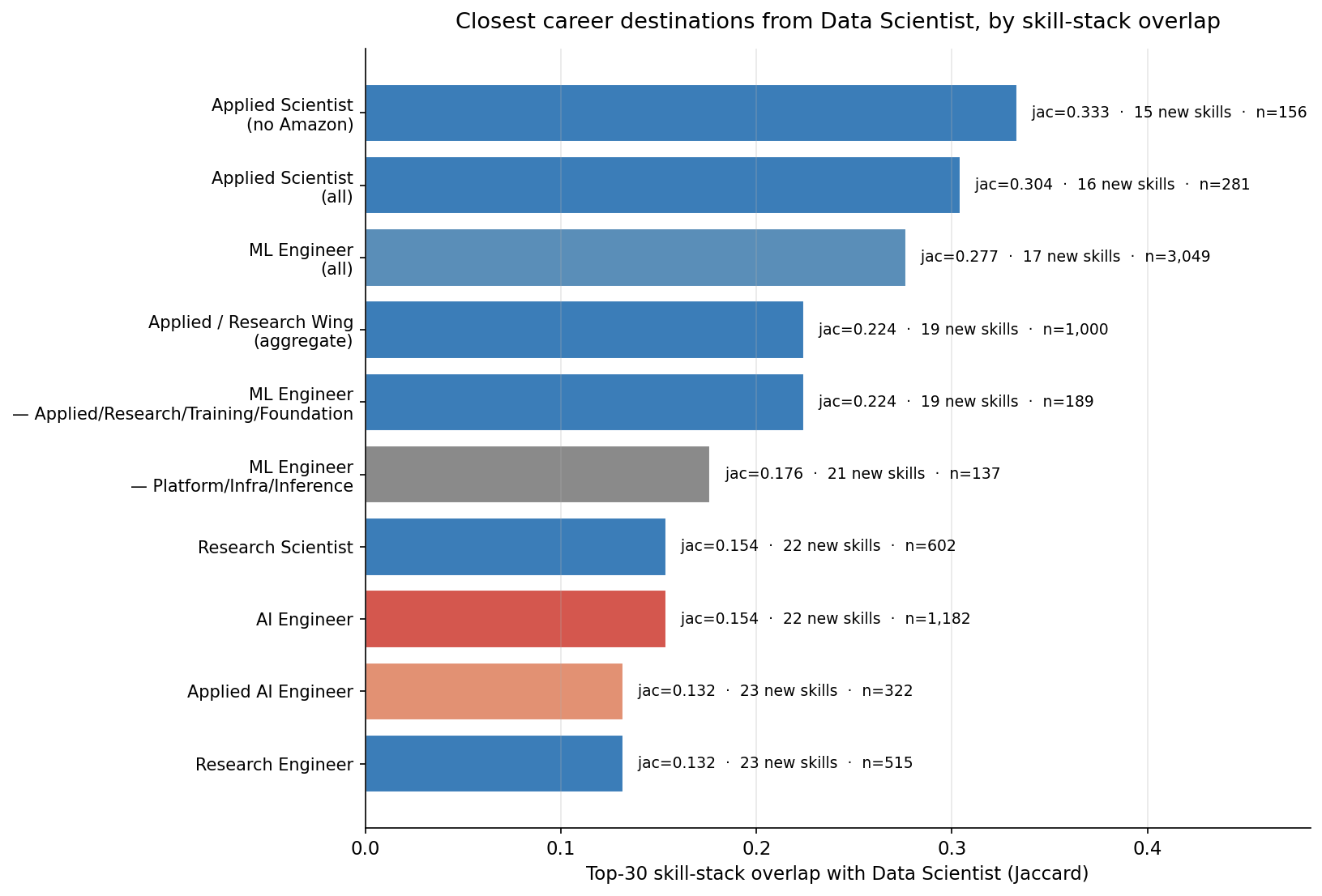 The roles built around training models — Applied Scientist, ML Engineer, the broader Applied/Research wing — share the most stack with Data Scientist. The roles built around orchestrating LLMs — AI Engineer, Applied AI Engineer — share the least.
The roles built around training models — Applied Scientist, ML Engineer, the broader Applied/Research wing — share the most stack with Data Scientist. The roles built around orchestrating LLMs — AI Engineer, Applied AI Engineer — share the least.
The Amazon-heavy Applied Scientist population (44% of those postings come from Amazon) is not driving the result. With Amazon excluded, Applied Scientist's Jaccard rises to 0.333. The closest single destination from Data Scientist by skill stack is non-Amazon Applied Scientist.
Get an email when we publish a new post. No account needed, unsubscribe anytime.
ML Engineer is two jobs hiding under one title
ML Engineer postings split visibly when you read the title suffix. Recruiters tag the team:
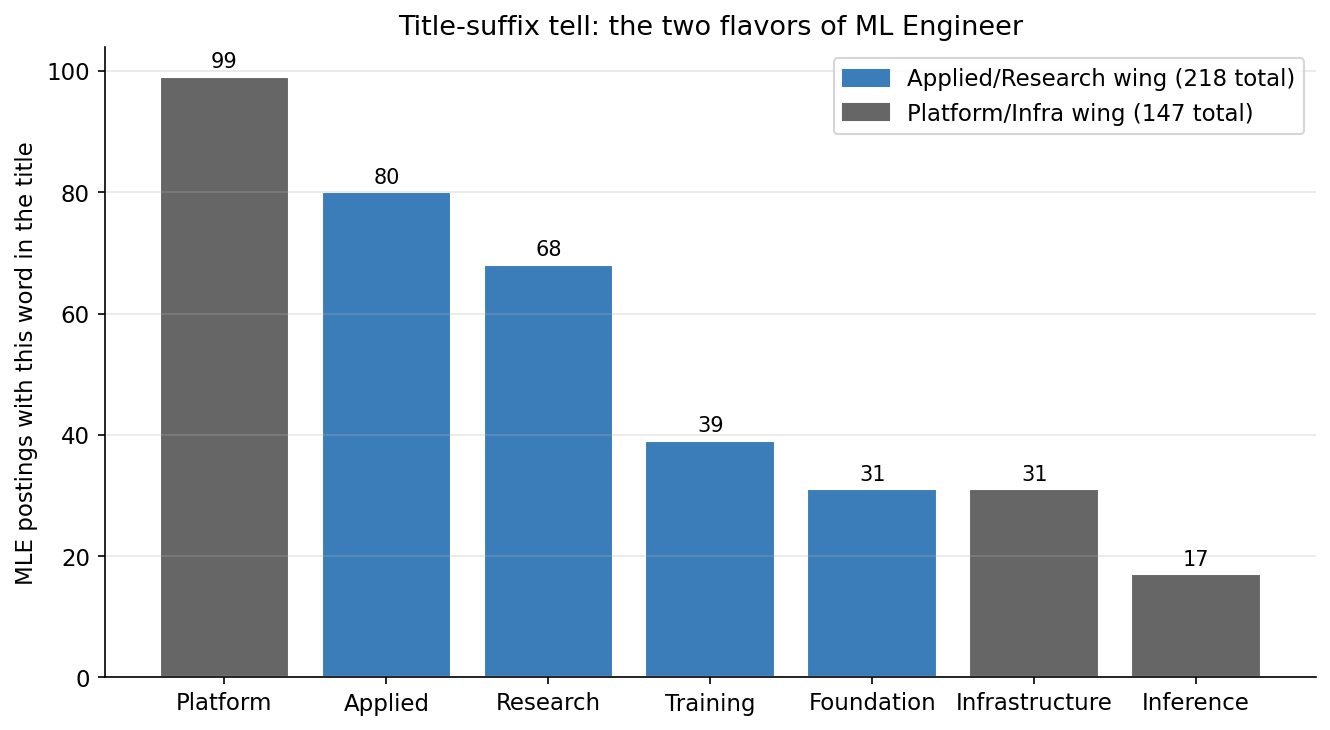 - "ML Engineer, Applied" / "ML Engineer, Research" / "ML Engineer, Training" / "ML Engineer, Foundation" — 218 postings.
- "ML Engineer, Applied" / "ML Engineer, Research" / "ML Engineer, Training" / "ML Engineer, Foundation" — 218 postings.
- "ML Engineer, Platform" / "ML Engineer, Infrastructure" / "ML Engineer, Inference" — 147 postings.
Pulling the skill profile separately for each wing makes the split obvious.
| Skill | Applied/Research wing (n=189) | Platform/Infra wing (n=137) |
|---|---|---|
| pytorch | 45.5% | 19.0% |
| deep learning | 21.7% | — |
| distributed training | 18.0% | — |
| fine-tuning | 16.4% | — |
| jax | 13.8% | — |
| reinforcement learning | 13.2% | — |
| transformers | 8.5% | — |
| foundation models | 7.4% | — |
| kubernetes | — | 18.2% |
| docker | — | 14.6% |
| observability | — | 13.9% |
| mlops | — | 13.9% |
| ci/cd | — | 13.1% |
| terraform | — | 10.2% |
| go | — | 7.3% |
| model serving | — | 6.6% |
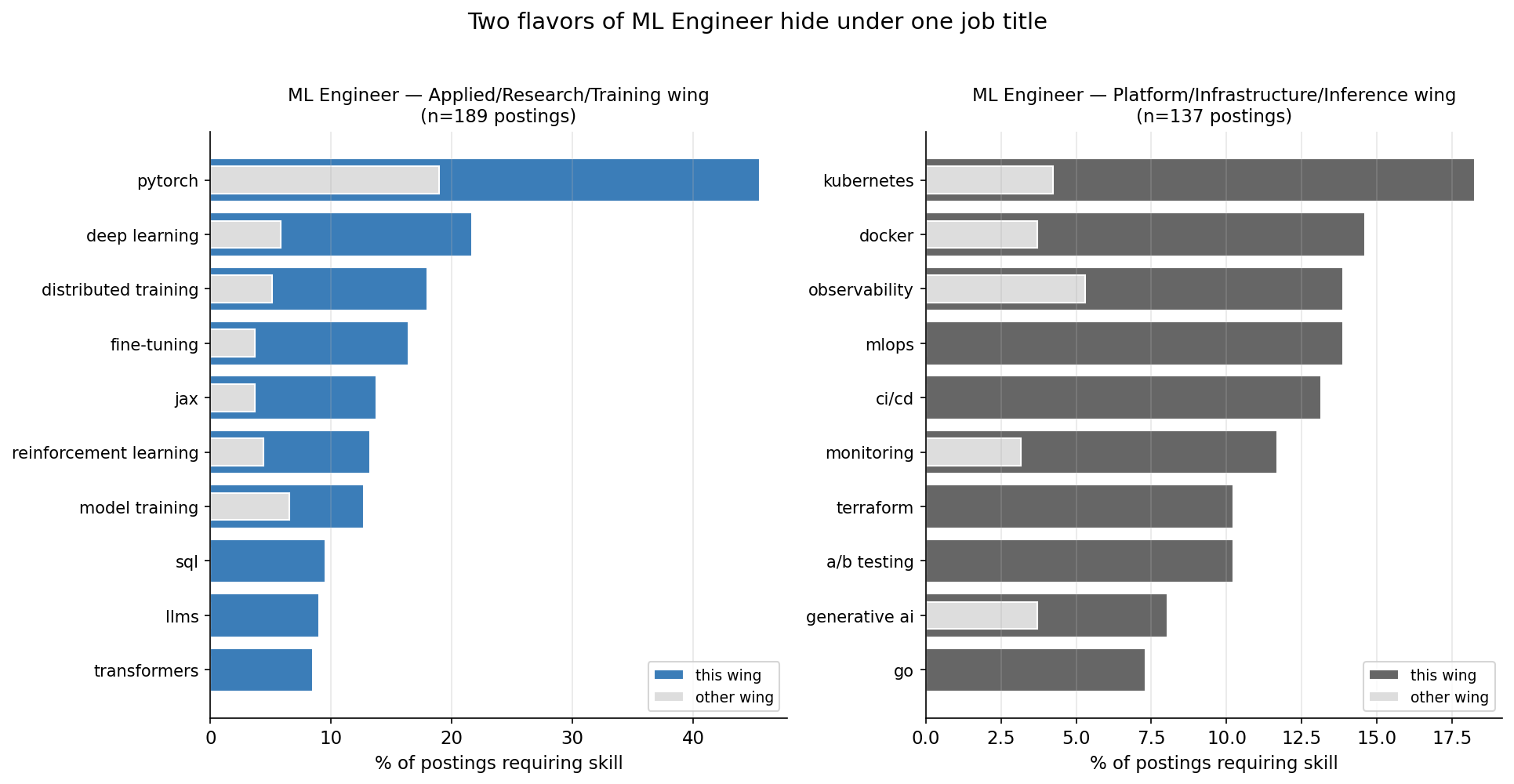 These are different jobs. The Applied wing trains models; the Platform wing operates them. The Applied wing's overlap with Data Scientist (Jaccard 0.224) is meaningfully higher than the Platform wing's (0.176).
These are different jobs. The Applied wing trains models; the Platform wing operates them. The Applied wing's overlap with Data Scientist (Jaccard 0.224) is meaningfully higher than the Platform wing's (0.176).
If a Data Scientist is moving toward an ML Engineer title, the natural destination is the Applied/Research wing — and that wing's skill stack is the one that overlaps most with the training-flavored work senior Data Scientists already do.
Three skill stacks, three jobs
Reading the same skill list across Data Scientist, the Applied/Research wing aggregate, and AI Engineer:
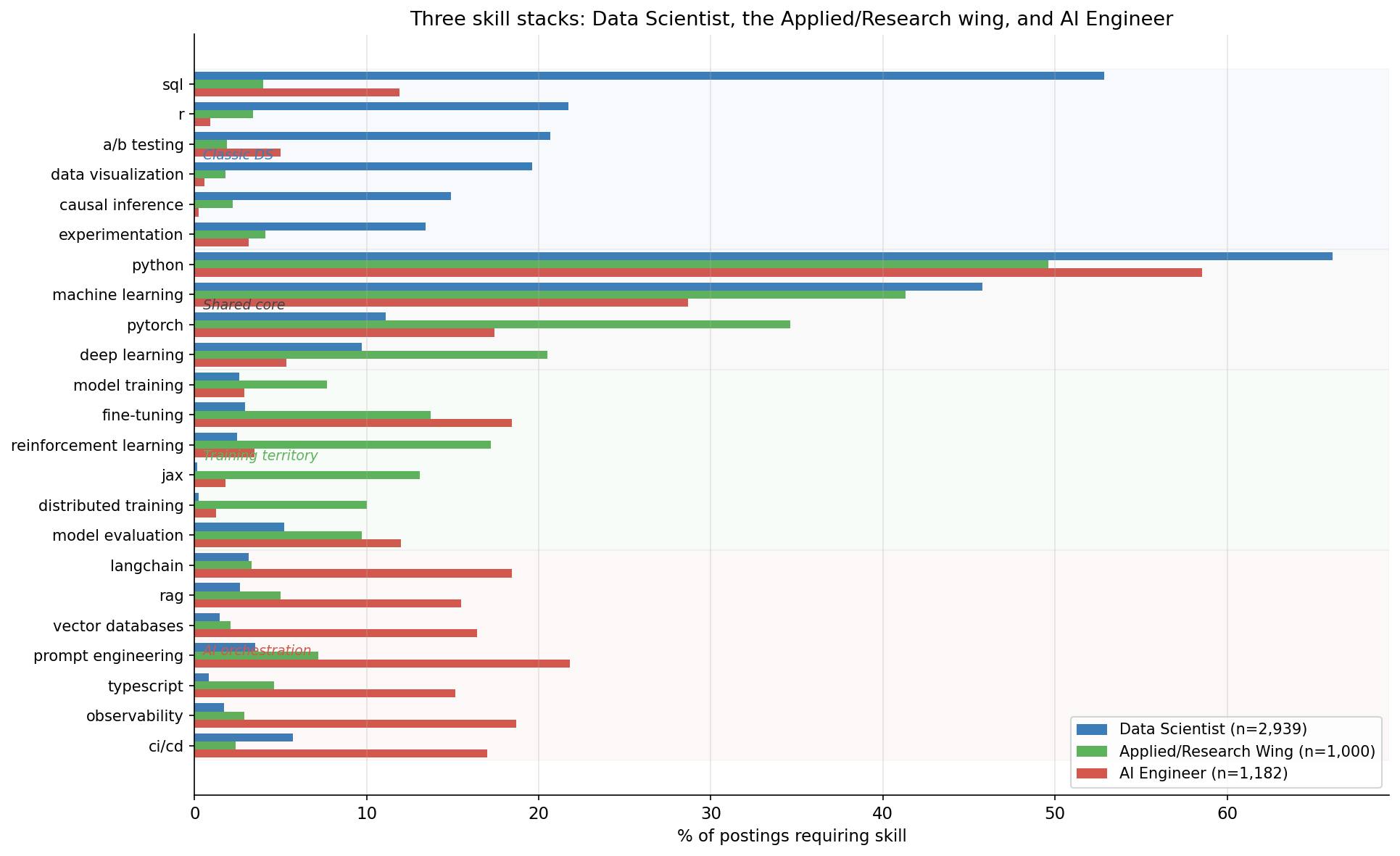 The chart has four regions:
The chart has four regions:
- Classic Data Scientist territory — SQL, R, A/B testing, causal inference, experimentation. The Applied/Research wing carries some of this. AI Engineer barely touches it.
- Shared technical core — Python, machine learning, PyTorch, AWS. All three roles draw from the same well; the difference is depth.
- Training territory — fine-tuning, model training, RL, JAX, distributed training. Heavy in the Applied/Research wing. Light in DS, light-to-moderate in AIE.
- AI orchestration territory — LangChain (18%), RAG (16%), vector databases (16%), TypeScript (15%), prompt engineering (22%), observability (19%). Almost exclusively AIE.
The map is clean. DS and AIE share a Python-and-ML core, but their distinctive skills barely overlap. The Applied/Research wing is the one cluster that covers DS's stats heritage and extends into training-flavored work.
What this means for your career
The labor-market data has an opinion on the popular DS → AIE narrative. The opinion is: it's a real role, the market is growing, and it's not a natural extension of a Data Scientist's skill stack. The natural extensions are roles built around training models — Applied Scientist, the Applied/Research wing of ML Engineer, the broader Applied/Research role family.
If you are choosing what to learn next as a Data Scientist:
- Shortest road: PyTorch depth, distributed training, fine-tuning, model evaluation. That maps onto Applied Scientist, ML Engineer (Applied/Research/Foundation), Research Engineer, and at frontier labs Research Scientist.
- Longest road: TypeScript, LangChain, RAG, vector databases, observability. A real and hireable destination, but it's an LLM-application engineer's stack. Treating it as the default upgrade for a Data Scientist understates the size of the leap.
- The bifurcated middle: ML Engineer is two jobs. Read the title suffix and the bullets carefully before applying.
Methodology
- Skills are pulled from each posting's resolved entity set (
entities[].label = "SKILL"). Lowercased canonical names; no further canonicalization. - ML Engineer aliases merged: "ML Engineer" + "Machine Learning Engineer". AI Engineer aliases merged similarly.
- Sub-archetype slices use
match_phraseontitlefor wing-defining tokens (Applied / Research / Training / Foundation vs Platform / Infrastructure / Inference) on top of the role filter. - Top-30, ≥5% threshold for overlap metrics. Lowering to top-50 / ≥3% does not change rank order.
- Amazon robustness check excludes
companyCanonicalName.keywordIN ("Amazon", "amazon") for the Applied Scientist slice. - This is cross-sectional;
ingestedAtcovers crawler runtime only and includes a backfill spike, so per-quarter trend claims are not made. - Big Tech (Google, Apple, Microsoft, Netflix, NVIDIA) is sparsely represented in the source index — findings should be read against that gap.
Full methodology, raw aggregates, and reproduction code on GitHub