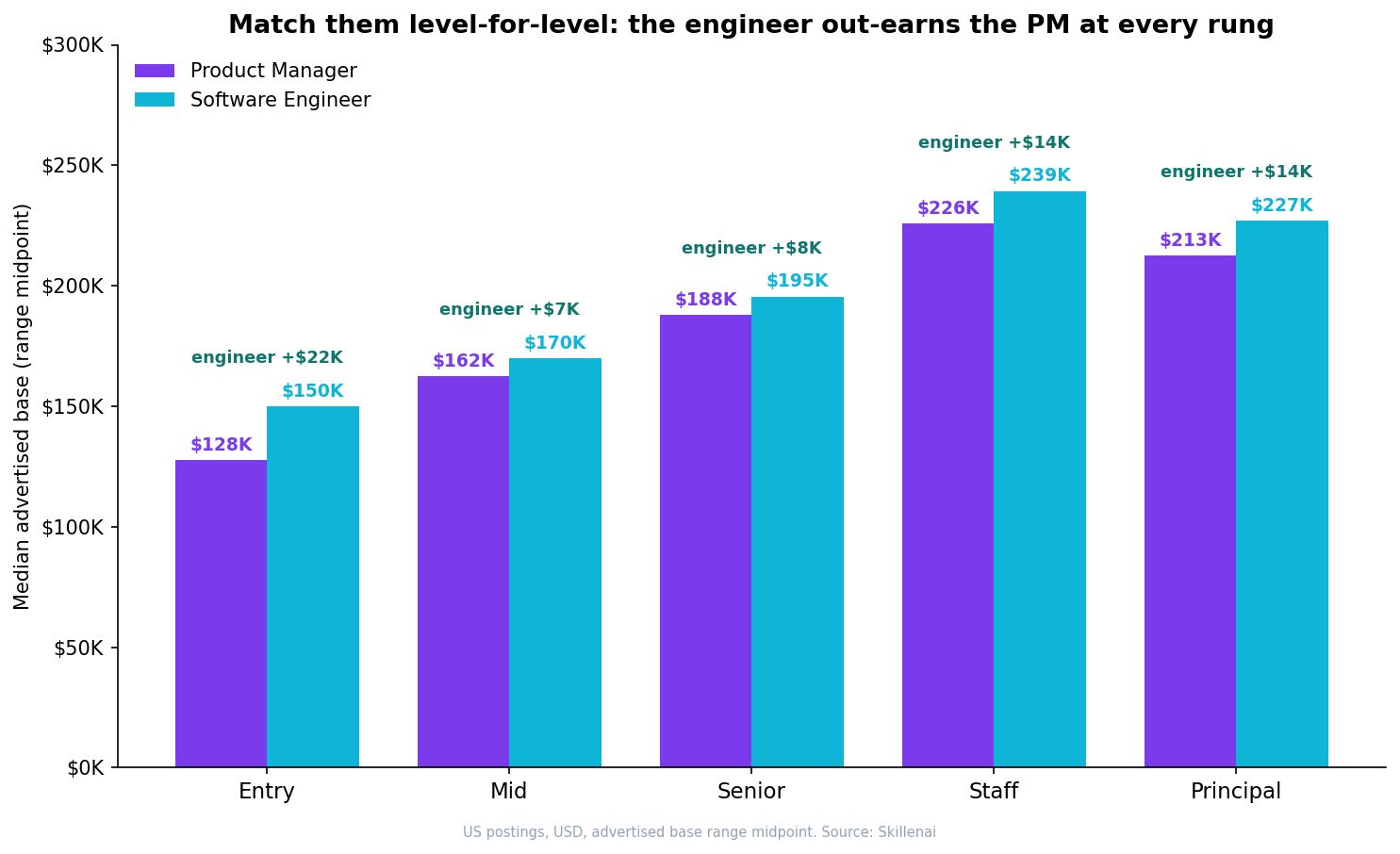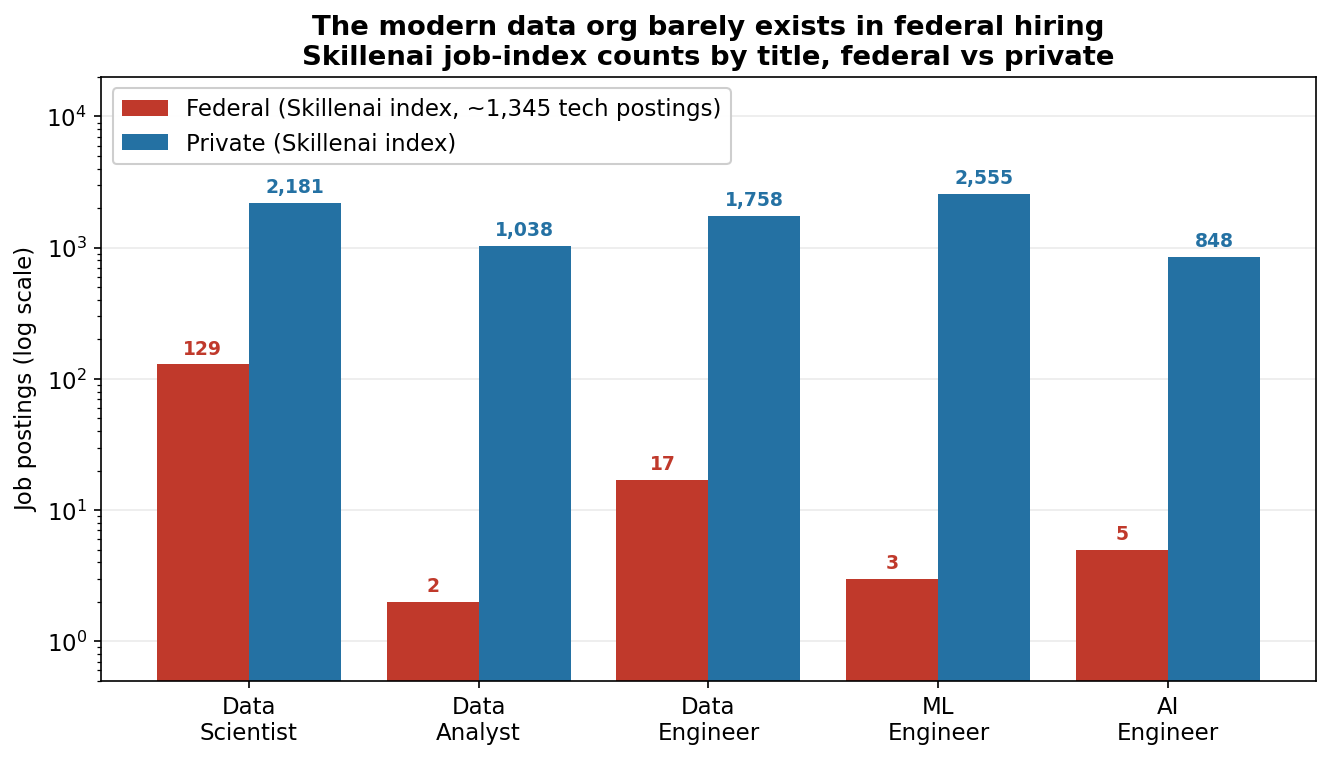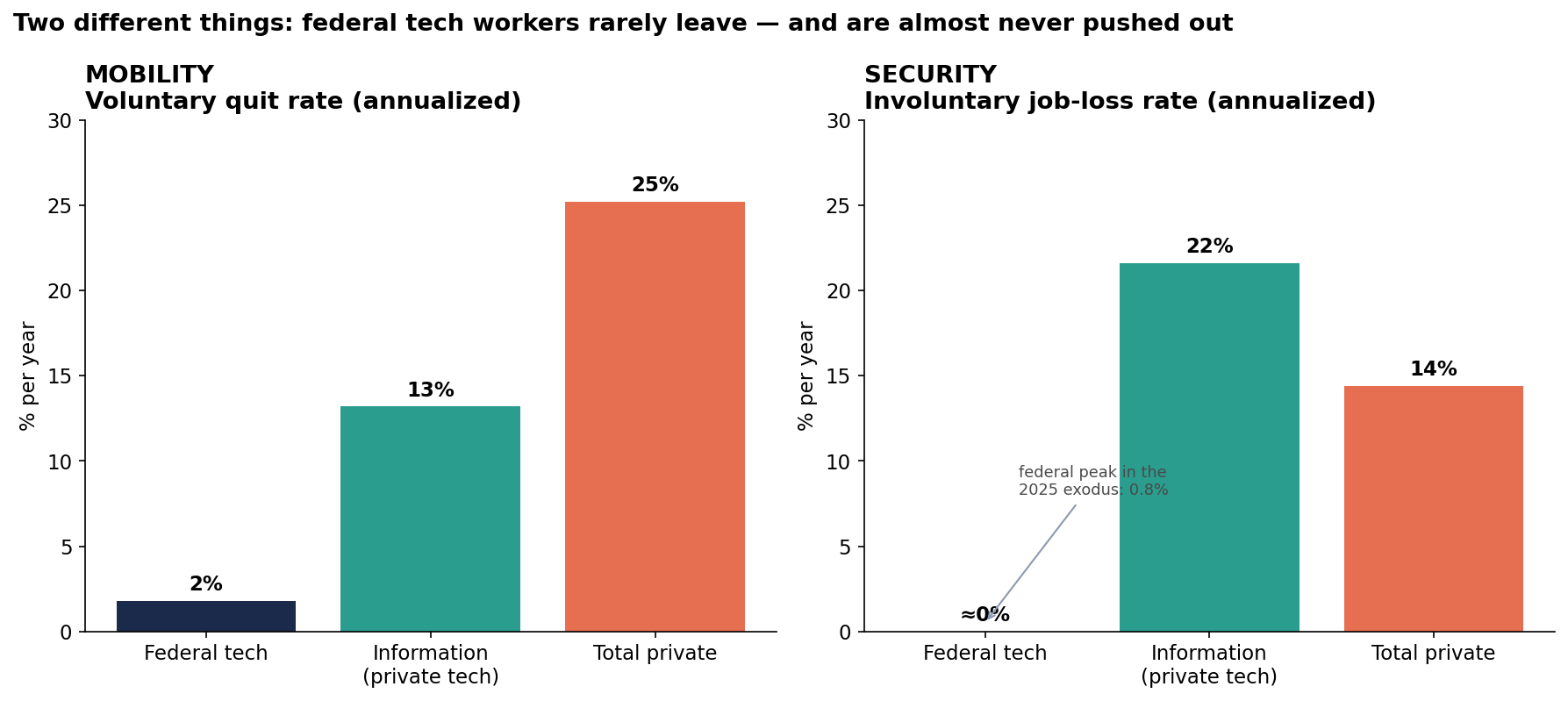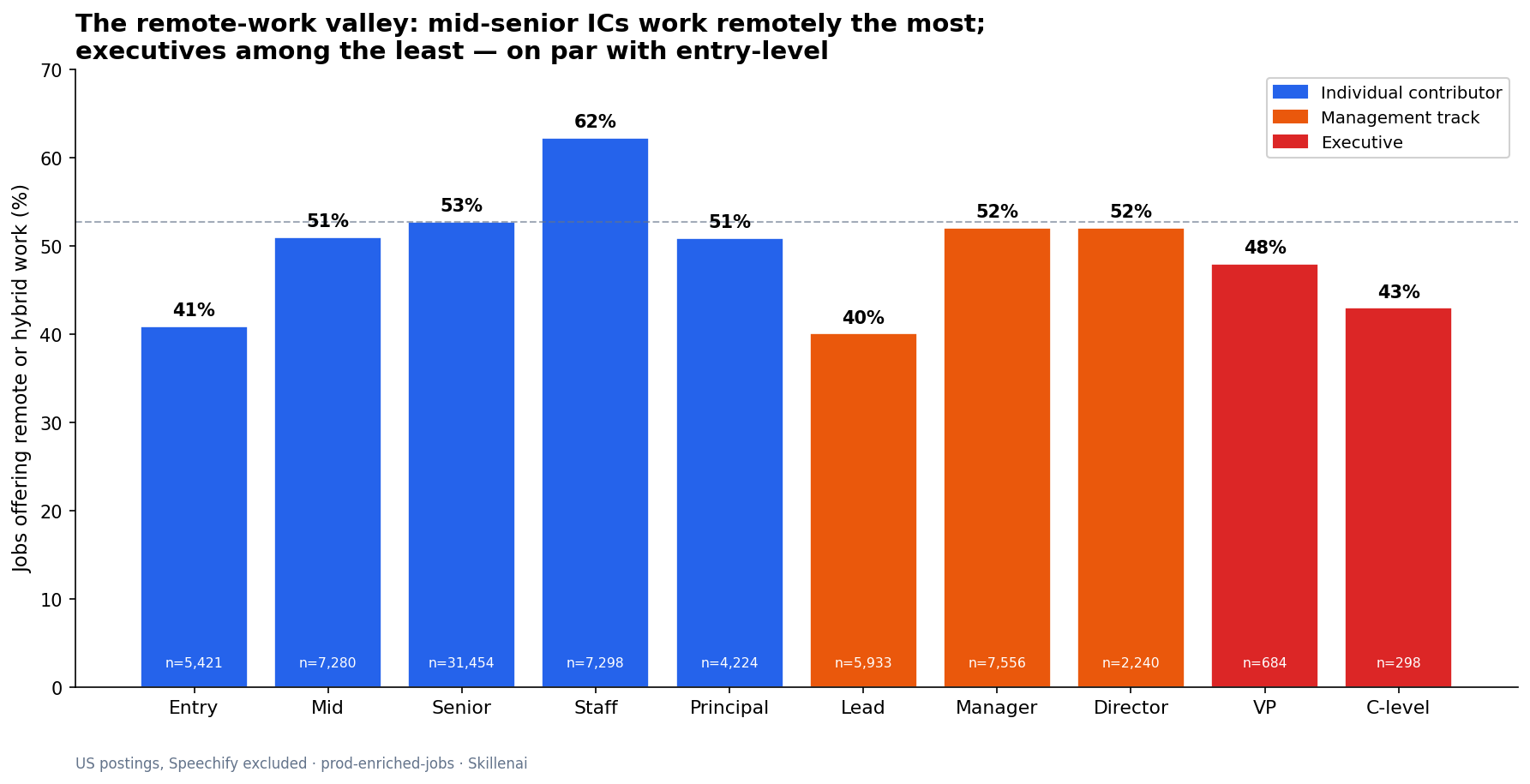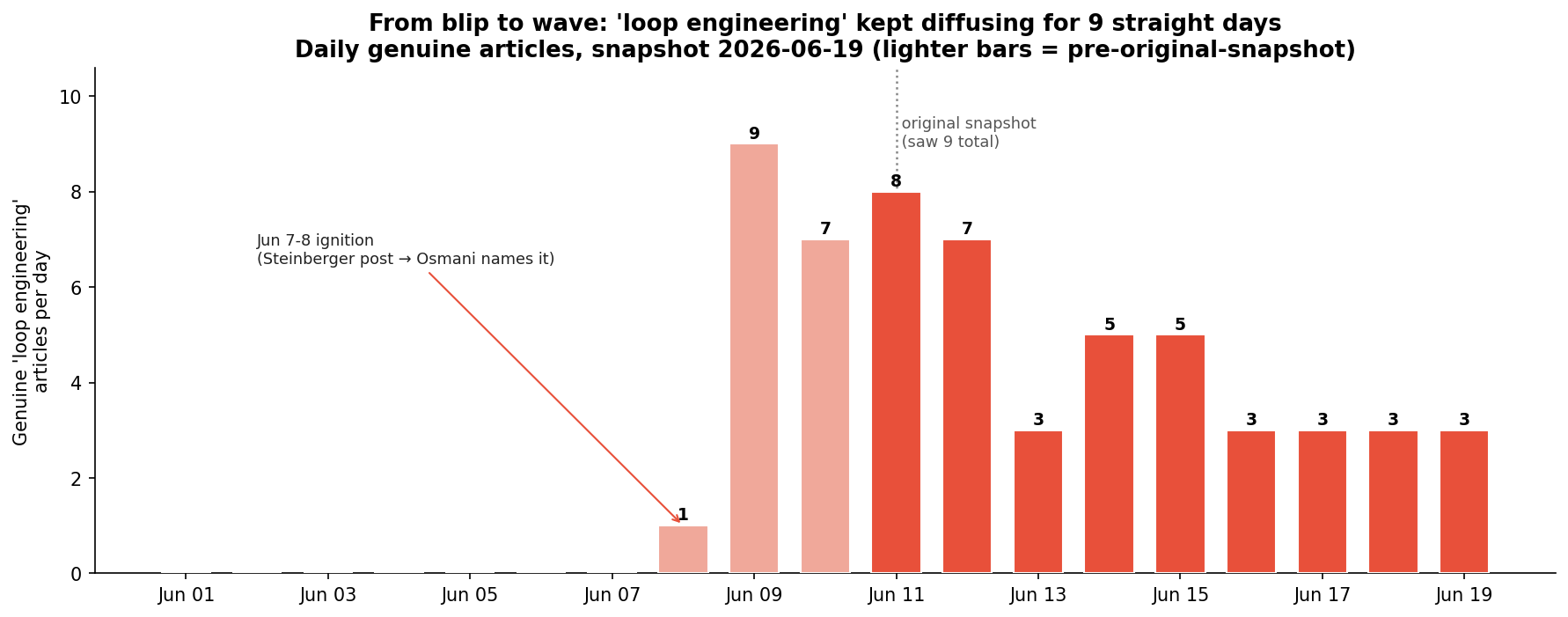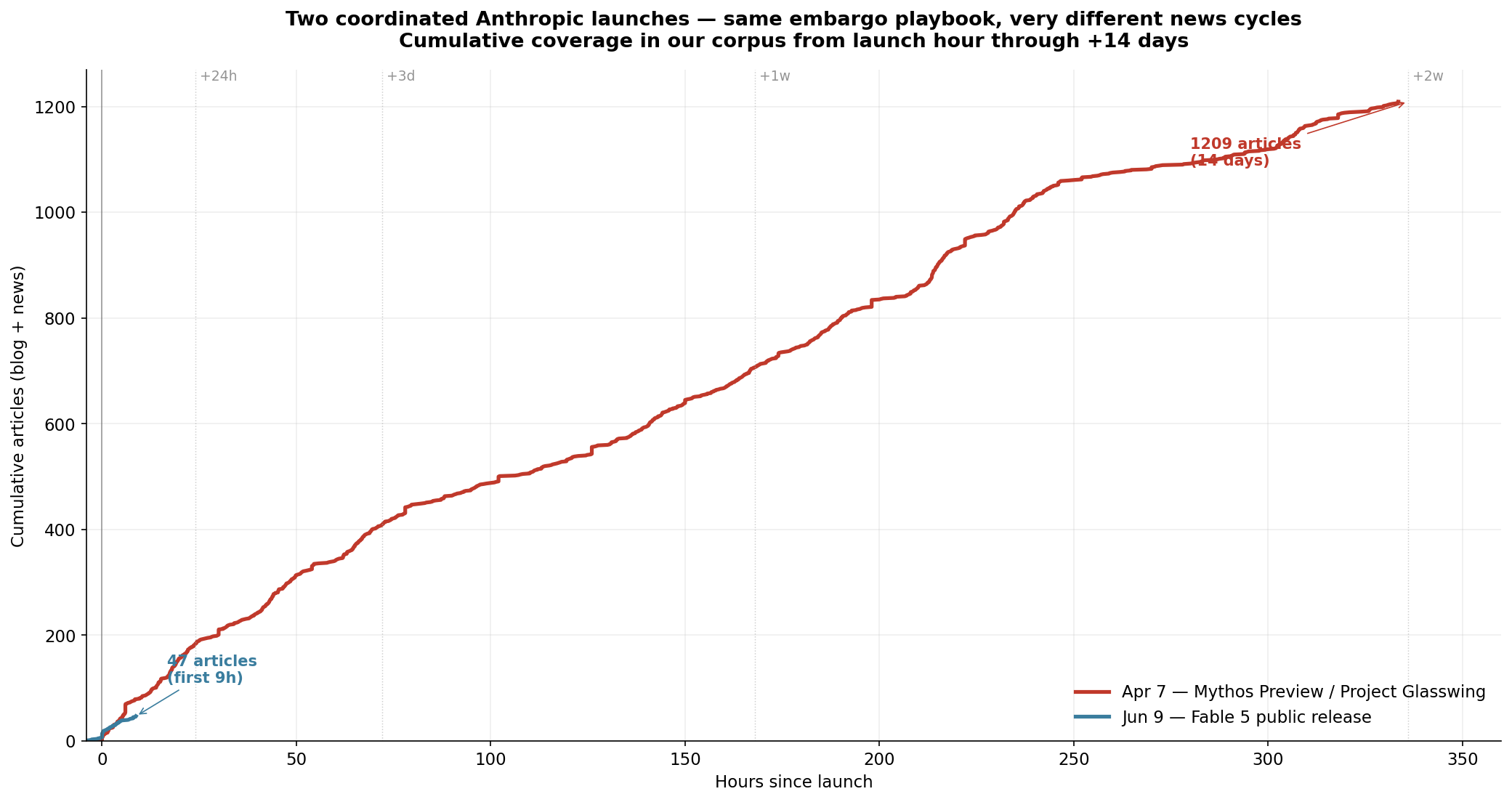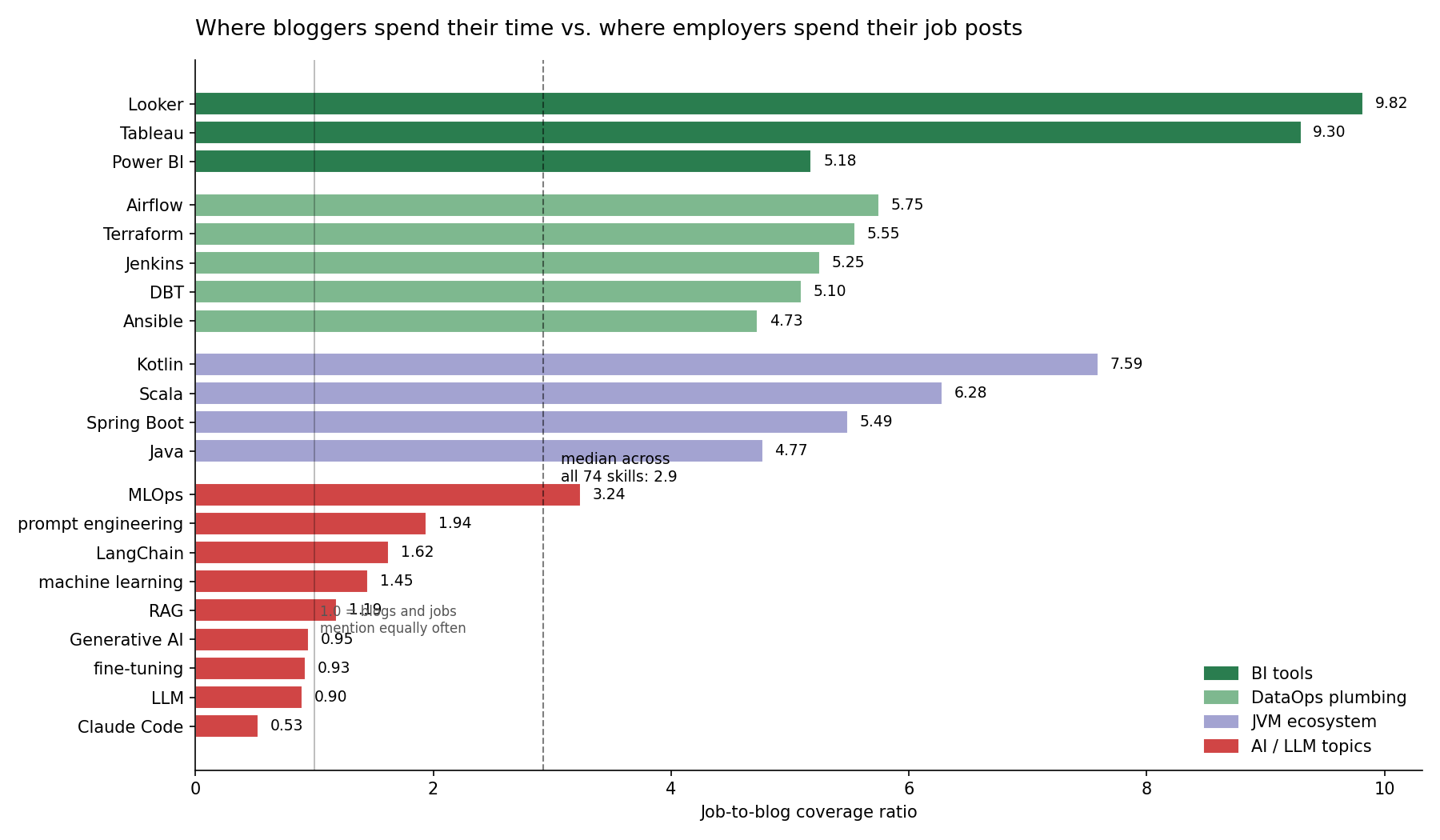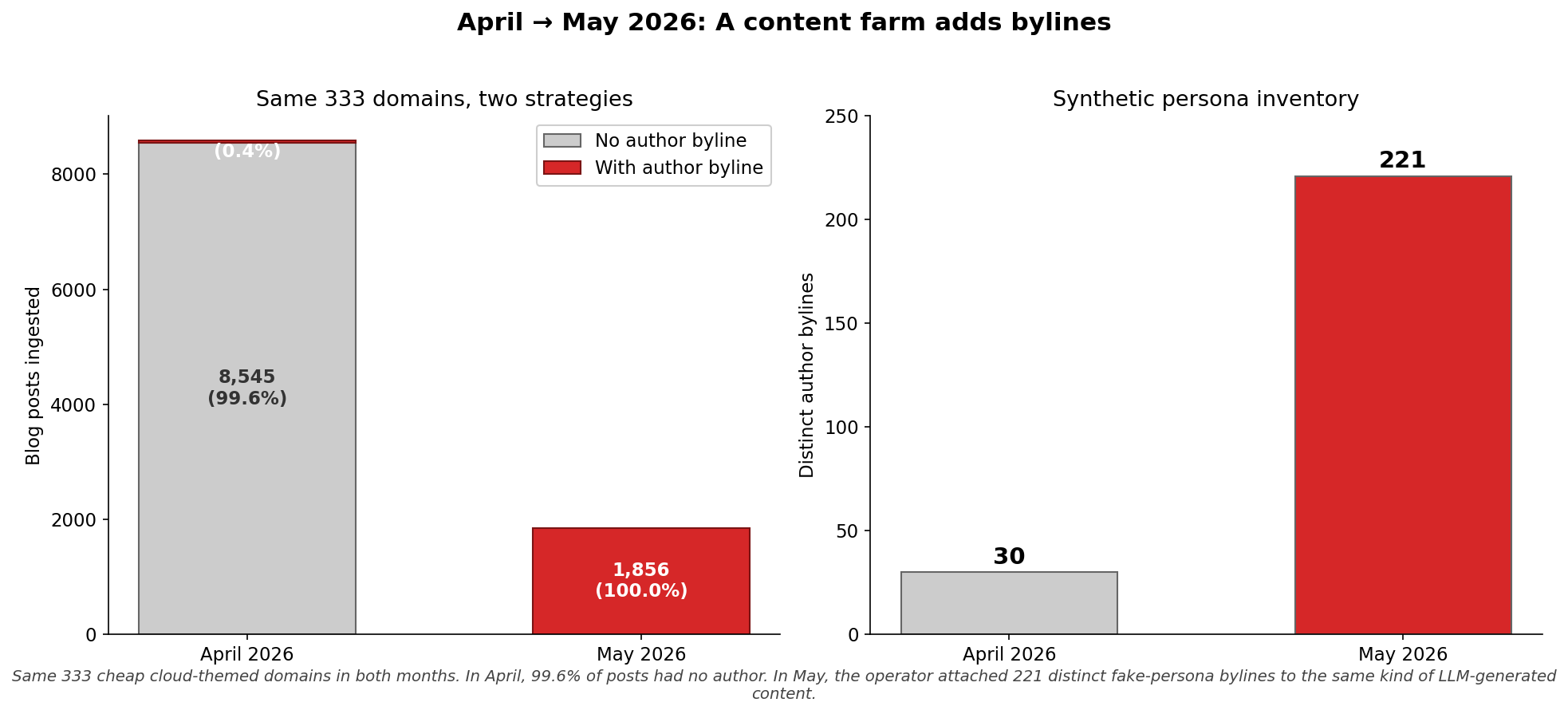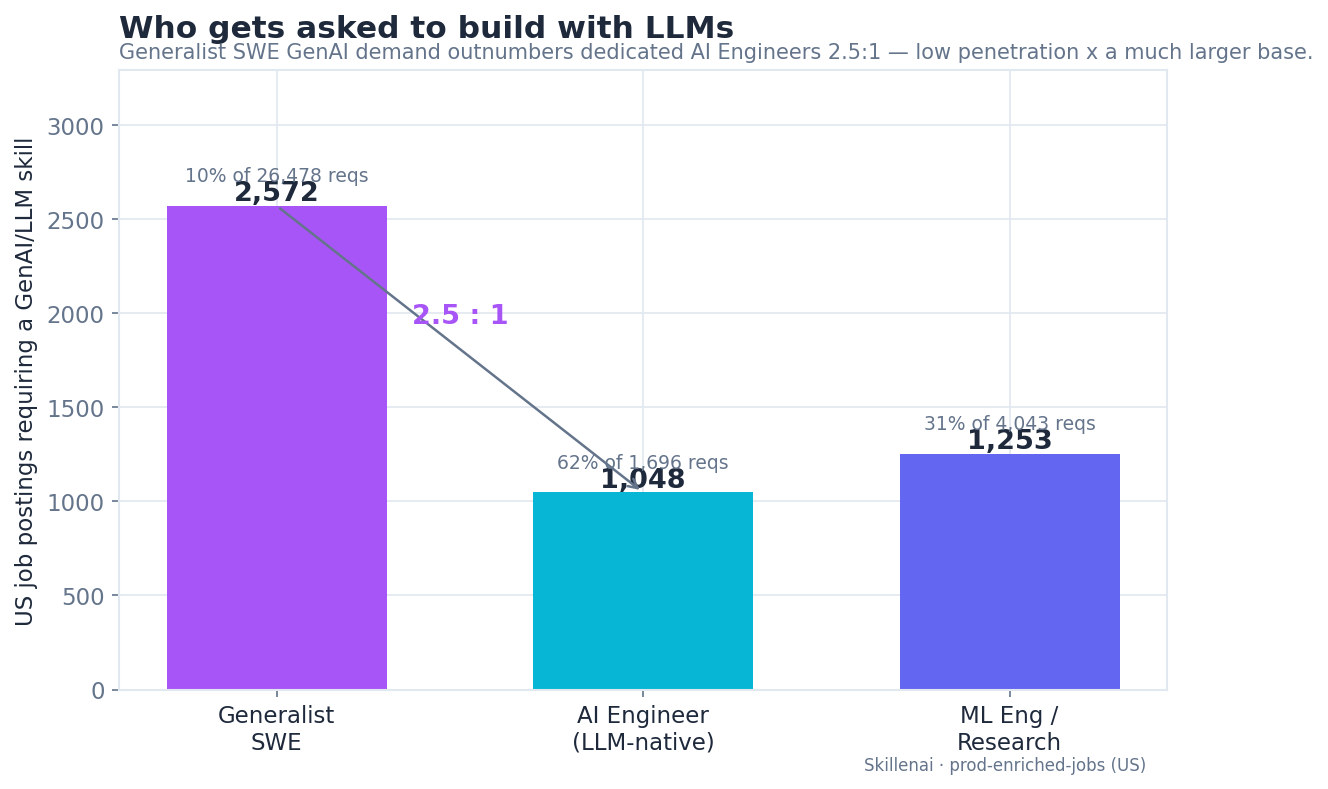
Who Actually Builds With LLMs: 2.5 Software Engineers for Every AI Engineer
US employers ask 2.5x more generalist software engineers than AI engineers to build with LLMs, and the generalists do it in TypeScript and Ruby, without LangGraph. A demand-side look at who really builds AI.
July 22, 2026