The Hardest Skill in the AI Job Market: JAX
Get an email when we publish a new post. No account needed, unsubscribe anytime.
The hardest skill in AI hiring is one most engineers have never written
We scored 222 AI/ML/DS skills on five independent difficulty signals — how senior the postings asking for it are, how much salary premium it commands, how scarce its supply is relative to demand, how concentrated its employers are, and how dense its vocabulary is when people write about it.
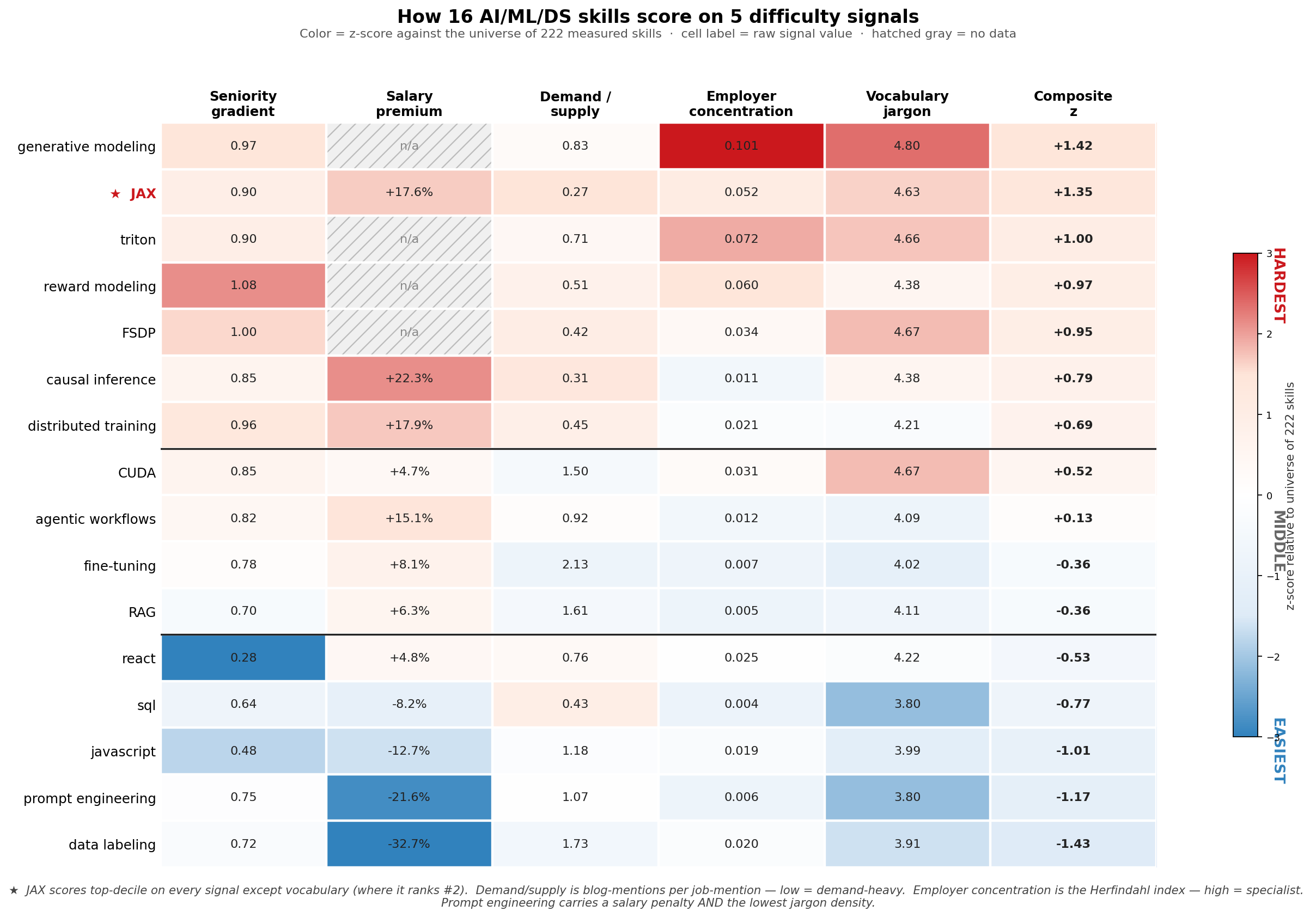
Out of 222 skills, exactly one scores positive on all five signals: JAX — Google's numerical-computing library that powers Gemini, Gemma, and parts of Claude.
Every other top-ranked skill has at least one cell missing or pointing the wrong way. Generative modeling and reward modeling sit higher than JAX on individual signals, but both have hatched-gray salary cells (too few USD-salaried postings to estimate). Causal inference pays more (+22.3%), but its employer concentration is below average. Distributed training pays nearly as much (+17.9%), but blogs about it are easier to find than blogs about JAX. Only JAX combines top-decile seniority, top-quintile salary, scarcest-of-the-tested-skills supply, top-decile employer concentration, and second-highest vocabulary jargon.
JAX carries a +17.6% salary premium controlling for role, country, and seniority. 90% of JAX postings are senior or above. It has the lowest supply-to-demand ratio in our 222-skill universe — 0.27 blog mentions per job mention, vs. transformer at 4.42. JAX postings concentrate at Waymo (18% top-1 share, plus Anthropic, Apple, Tesla autonomy teams), giving it specialist-level employer concentration. And blog articles about JAX use the second-densest technical vocabulary in our corpus (mean per-document IDF of 4.63 vs. 3.80 for prompt engineering and SQL).
That fifth signal is the one that ties the others together. JAX isn't an academic concept — it's a tool. The papers that use it cite the methods, not the framework. So you can't pick up JAX by reading papers; you pick it up by writing code in it. And the code is mostly only written inside frontier AI labs — which is why every other signal also points the same way.
What is JAX, exactly?
For readers who haven't worked with it: JAX is Google's numerical-computing library — a NumPy-shaped API plus a compiler. Think of it as PyTorch's quieter, more academic sibling. It does three things PyTorch doesn't do natively:
- JIT compile Python functions to fused GPU/TPU kernels via Google's XLA compiler. The same Python code can run 100× slower or 100× faster depending on whether you've expressed it in a way XLA can fuse.
- Functional transformations —
grad,vmap(auto-batching), andpmap(auto-multi-device parallelism) compose like Lego. You write a single-example loss function, andvmapandpmapgive you batched and parallelized versions for free. - Purely functional model code — no in-place mutation. Every model is a function from
(params, inputs)tooutputs. State is passed through explicitly.
Who uses it: Google DeepMind (Gemini, Gemma), Anthropic (Claude — partly), Apple's research arm, Waymo, and a handful of academic groups. Most of the open-source ecosystem outside that orbit — Hugging Face, the LLaMA family, LangChain — runs on PyTorch.
Why it's hard to learn: the functional / pure-function model is genuinely different from PyTorch's eager mode. There's no Stack Overflow safety net for the corner cases. Most JAX questions get answered by Google researchers in GitHub issues, not by tutorials. The compiler errors are notoriously inscrutable. You can't "vibe-code your way through" because the JIT will surface every shape mismatch and side-effect at trace time.
Companies that need JAX need engineers who can debug XLA compile failures, design SPMD parallelism across TPU pods, and write functional model code without leaking state. None of this is bootcamp material. It's the skill you reach after 5–10 years of ML engineering, after PyTorch is muscle memory.
How we measured difficulty — five signals, intentionally complementary
Job postings tell you which skills employers want, not which ones are hard. We built five independent proxies for difficulty and z-scored each one against the universe of 222 measured skills.
Seniority gradient. Share of IC postings requiring the skill at each band (entry/junior/mid/senior/staff/principal). High = appears almost exclusively at senior+ — proxy for "the labor market does not believe juniors can do this."
Salary premium. Hedonic Ridge regression on log USD midpoint salary across 26,527 USD-salaried postings, with one-hot role/country/seniority controls. Per-skill coefficients are partial elasticities — the salary delta a posting carries when it lists a skill, holding role, location, and seniority fixed. 144 skills with N≥30 USD-salaried postings make the regression panel.
Supply / demand ratio. Per-skill match_phrase count in the technical-topic-filtered blog corpus, divided by the same count in the job-posting corpus. Low ratio = high demand relative to supply = scarcity signal. JAX scores 0.27 (the lowest of any tested skill), transformer scores 4.42 (saturated blog community).
Employer concentration (HHI). Herfindahl-Hirschman index of postings-per-employer in our role-relevant job sample (Amazon excluded as a known JD-template confound). High HHI = specialist skill concentrated at a few frontier employers. Triton 0.072 (Graphcore-heavy) and JAX 0.052 (Waymo-heavy) are the cleanest specialist signals.
Vocabulary jargon (mean IDF). From a 2,736-document technical-blog corpus, we built a word-level IDF model (vocabulary 22K terms, document-frequency ≥2 filter). For each skill, we fetch its top 30 technical-topic blog matches, tokenize, look up each token's corpus IDF, and average. Skills whose articles use rare technical vocabulary score high. CUDA (4.67) and JAX (4.63) top this signal. Prompt engineering and SQL bottom out at 3.80.
The composite is the equal-weight average of the five z-scores. Skills missing one signal get a z=0 contribution for that dimension.
We're not measuring "how many hours did this take to learn for you." We're measuring how the labor market treats a skill — who it hires for it, what it pays for it, where it talks about it, and what other skills it expects alongside it.
What the easy end looks like
The bottom of the composite is just as informative.
| Skill | Sen grad | Salary | S/D ratio | HHI | Mean IDF | Composite z |
|---|---|---|---|---|---|---|
| Prompt engineering | 0.75 | −21.6% | 1.07 | 0.006 | 3.80 | −1.17 |
| Data labeling | 0.72 | −32.7% | 1.73 | 0.020 | 3.66 | −1.43 |
| JavaScript | 0.48 | −11.2% | 1.18 | 0.019 | 3.99 | −1.01 |
| SQL | 0.64 | −8.2% | 0.43 | 0.004 | 3.80 | −0.77 |
| React | 0.28 | +4.8% | 1.41 | 0.022 | 4.22 | −0.53 |
Prompt engineering carries a −21.6% salary coefficient — among the most negative in the entire 144-skill regression panel. It also has the lowest jargon density tied with SQL (3.80 mean IDF) and one of the lowest employer concentrations (HHI 0.006 — every employer wants it, none of them in particular). The labor market signals consistently across four signals that prompt engineering is a commodity skill — the kinds of jobs that explicitly recruit for it tend to be at companies and price points that don't pay frontier-model rates.
This is a sharp contrast with agentic workflows (+15.5% salary) and agent architectures (concentrated at Anthropic, top-1 employer share 39%) — both AI Engineer-adjacent skills that do command specialist-level signals. The labor market discriminates within "AI Engineer" by technical depth: prompt engineering is at the bottom; agent design and orchestration work is at the top.
What this means for transitioning between AI/ML roles
If we anchor at Data Scientist and walk to each adjacent role on the AI/ML taxonomy, the standard Jaccard skill-set overlap from our previous post gives us a "paper distance." But Jaccard treats every missing skill as equally costly to acquire. When we replace it with the sum of difficulty z-scores over the missing skills, the rank order shifts.
![]() Five roles move up in the ranking when measured by effort instead of paper distance:
Five roles move up in the ranking when measured by effort instead of paper distance:
- Research Engineer — #2 by Jaccard, #1 by effort.
- Research Scientist — #4 by Jaccard, #2 by effort. The missing skills are the entire research peak: generative modeling, JAX, distributed training, RL, post-training. All top-decile difficulty.
- MLE / Platform-Infrastructure-Inference — #5 by Jaccard, #3 by effort.
- MLE / Applied-Research wing — #8 by Jaccard, #4 by effort.
- Applied/Research Wing aggregate — #7 by Jaccard, #5 by effort.
Three roles move down:
- AI Engineer — #3 by Jaccard, #8 by effort. The missing skills are LangGraph, vector databases, RAG, observability, MLOps, prompt engineering — the bottom half of the difficulty distribution. AI Engineer looks like the longest paper-jump from a Data Scientist resume but is actually the easiest role transition in effort terms.
- Applied AI Engineer — #1 by Jaccard, #6 by effort.
- Applied ML Engineer — #6 by Jaccard, #9 by effort.
Every research-track and MLE-track role gets harder; every AI Engineer-track role gets easier. The shape of the difficulty universe is completely separable: the AIE family lives in the bottom half of the universe; the research / MLE family lives in the top half.
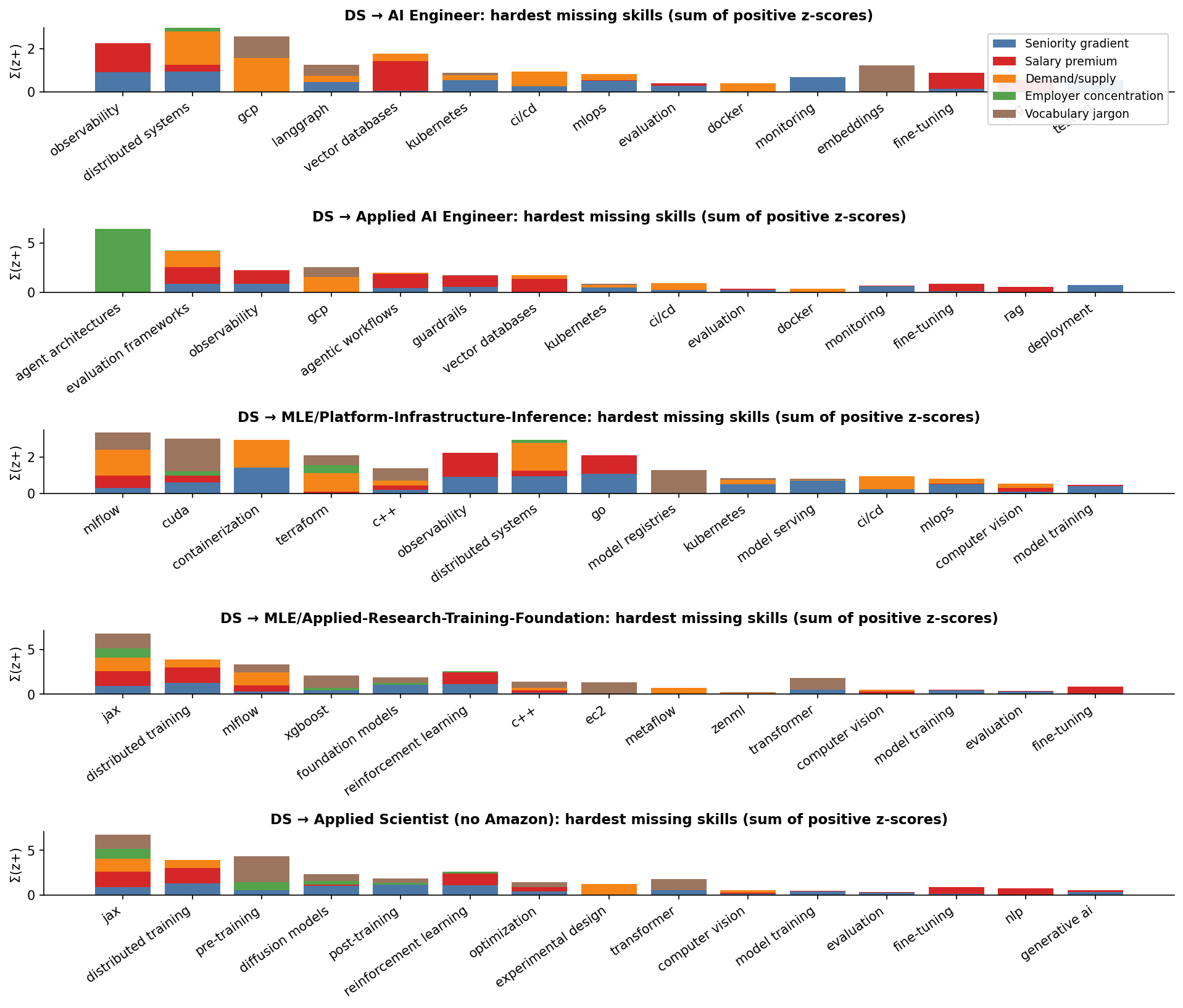 The shape of each transition's bar chart is its own diagnostic. AI Engineer has many short bars (many easy missing skills); Applied AI Engineer has a tall green bar on agent architectures (Anthropic-concentrated specialist signal); MLE-Platform mixes blue + green (operational seniority + specialist concentration); Applied Scientist has tall brown + green bars (research-jargon + research-concentration). They reach similar total effort gaps in different ways.
The shape of each transition's bar chart is its own diagnostic. AI Engineer has many short bars (many easy missing skills); Applied AI Engineer has a tall green bar on agent architectures (Anthropic-concentrated specialist signal); MLE-Platform mixes blue + green (operational seniority + specialist concentration); Applied Scientist has tall brown + green bars (research-jargon + research-concentration). They reach similar total effort gaps in different ways.
What this means for your career
For Data Scientists choosing what to learn next, the data has an opinion that's more nuanced than "move up the salary curve" or "follow the AI Engineer wave."
- If you want the highest-paying skills, look at causal inference (+22.3%), distributed training (+17.9%), evaluation frameworks (+17.7%), JAX (+17.6%), agentic workflows (+15.5%), or PyTorch (+18.5%). Scattered across MLE, Research Engineer, and the more technical end of AI Engineer.
- If you want the most specialist concentration (smallest universe of employers, but highest paying when you crack in), look at agent architectures (Anthropic), JAX (Waymo + frontier labs), triton (Graphcore), or reward modeling (Anthropic).
- If you want the smallest set of new skills, but you're willing to learn the hardest possible ones, the answer is Applied Scientist (no Amazon) at 15 missing skills — but those 15 are the research peak.
- If you want the easiest skills to learn, period, the answer is AI Engineer at avg difficulty 1.17. Most of the missing skills are LangGraph, vector databases, RAG, observability, MLOps — the labor market revealed-prefers these as commodity.
The combination most career advice ignores is short jump + hard skills (Applied Scientist) versus long jump + easy skills (AI Engineer). Both can be defensible career moves; they're just optimizing different things.
Methodology and caveats
Five signals, intentionally complementary. Two earlier signals (academic-depth ratio and prerequisite-DAG depth) were dropped from this version after EDA showed they didn't add information independent of the other four — the academic-depth ratio biased entirely toward research over engineering, and the prerequisite-DAG resolution was too coarse (>85% of skills landed at depth 0–2). The five signals we kept each measure different facets: seniority is on the candidate side, salary is the market premium, supply/demand combines content and labor markets, employer concentration is on the demand side, vocabulary jargon is on the content side.
Market-revealed difficulty, not personal difficulty. Every signal is a proxy for what employers want, not for how many hours an individual would need to acquire a skill.
Salary regression details. R² = 0.68 on 26,527 USD-salaried postings; Ridge with one-hot role/seniority/country and a sparse skill matrix. We filtered out 462 postings (1.7% of the salary sample) with empty companyCanonicalName and a templated 15-skill boilerplate — an entity-extraction artifact that distorted coefficients on a handful of skills (notably "inference" jumped to a fake +48% before filtering). Read coefficients as a comparative ranking, not as point estimates of a causal premium. Multicollinearity between conceptually-overlapping skills (e.g. "GenAI" and "prompt engineering") is a known limitation of the spec; bootstrap CIs to flag unstable coefficients are a planned follow-up.
Salary regression covers 144 skills with N≥30 USD-salaried postings. Skills below the cutoff (most of the research peak — generative modeling, reward modeling, FSDP, representation learning, etc.) get a salary-z of 0 in the composite. We can't say JAX pays more than reward modeling because we don't have enough USD-salaried reward-modeling postings to estimate a coefficient.
Employer concentration excludes Amazon. Amazon's recruiter-side JD template tags an enormous boilerplate skill list ('algorithms and data structures', 'unix/linux', 'parallel and distributed computing', 'numerical optimization', 'mxnet') across most of their AI/ML postings, producing fake near-100% concentration on terms that are otherwise generic. The same artifact already caveats the Applied Scientist role bucket.
Blog corpus filtered to technical topics. Without filtering, "JAX" matches Tumblr posts about a fictional character named Jax, and "Spark" matches band reviews. We restricted blog queries to documents whose topics field contains at least one of: machine-learning, deep-learning, ml, llm, generative-ai, mlops, ai, software-engineering, devops, data-science, computer-vision, nlp, etc. This eliminated the noise floor for ambiguous skill names.
IDF model details. Built from a 2,736-document technical-topic blog sample, vocabulary 22,272 terms after a df≥2 filter to suppress typos. Per-skill scores use the median of mean per-document IDF across the top 30 technical-topic blog matches.
Big Tech under-represented. Postings from Google, Apple, Microsoft, NVIDIA are mostly absent (proprietary ATS platforms not scraped). For skills concentrated at Google in particular — JAX, TPUs, XLA — the prevalence and salary numbers are lower bounds on the actual market.
No time series. This is a cross-sectional snapshot of 2026-Q2 hiring data.
Full methodology, per-signal CSVs, and all 222 skill scores on GitHub.