Popular Python Packages for Data Science
Get an email when we publish a new post. No account needed, unsubscribe anytime.
Essential Python Packages for Data Science
The vast majority of data science workflows utilize these four essential Python packages.
I recommend using Anaconda to setup your Python environment. One of it's many benefits is that it automatically installs these 4 libraries, along with many other essential Python packages for data science.
Numpy
The fundamental package for scientific computing with Python.
Numpy is foundational for data science workflows because of it's efficient vector operations. The Numpy ndarray is a workhorse for mathematical computations in tons of useful libraries.
Pandas
pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language.
The Pandas dataframe is the primary data object for most data science workflows. A dataframe is basically a database table, with named columns of different data types. Numpy ndarrays, in contrast, must have the same data type for each element.
Scikit Learn
Simple and efficient tools for predictive data analysis
Scikit Learn is the workhorse for machine learning pipelines. It's built on top of Numpy and Matplotlib, and plays nice with Pandas. Scitkit Learn offers implementations of almost every popular machine learning algorithm, including logistic regression, random forest, support vector machines, k-means, and many more.
Matplotlib
Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python.
Matplotlib is the foundational data visualization package for Python. Pandas and Scikit Learn both have handy visualization modules that rely on Matplotlib. It's a very flexible and intuitive plotting library. The downside is that creating complex and aesthetically pleasing plots usually requires many lines of code.
Visualization Packages
My two favorite Python visualization packages for data science are both built on top of Matplotlib.
Seaborn
Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics.
Seaborn makes beautiful statistical plots with one line of code. Here's a few of my favorite examples.
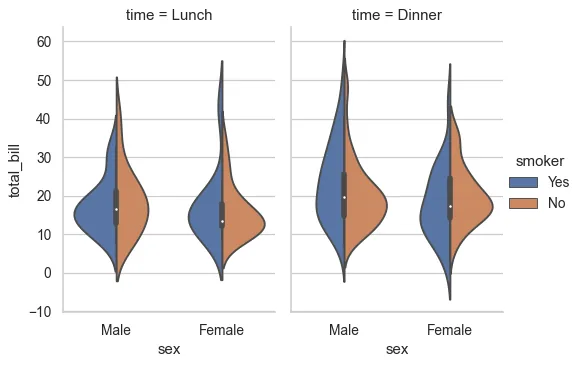
A violin plot made with the Seaborn data visualization Python package can help you visualize the distribution of a variable for various slices. The violin plot displays a box and whisker plot along with a kernel density estimate of the distribution.
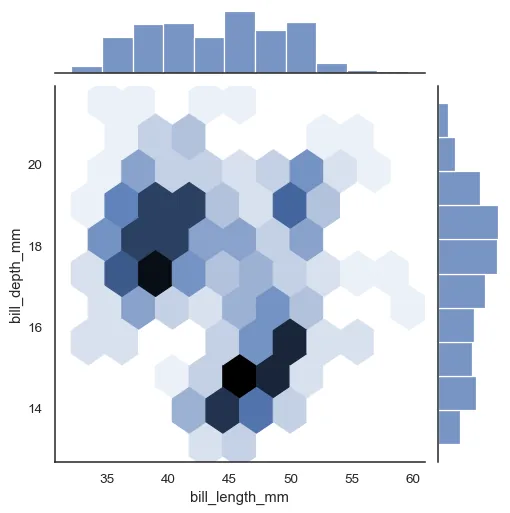
A joint plot made with the Seaborn data visualization Python package can help you visualize the joint distribution of two variables. The joint plot is similar to a scatter plot, but shows the density of values instead of individual observations. It also shows the univariate distributions on each axis.
Scikit Plot
There are a number of visualizations that frequently pop up in machine learning. Scikit-plot generates quick and beautiful graphs and plots with as little boilerplate as possible.
Scikit Plot provides one-liners for many common machine learning plots, including confusion matrix heatmaps, ROC curves, precision-recall curves, lift curves, cumulative gains charts, and others. Here's a slideshow of examples.
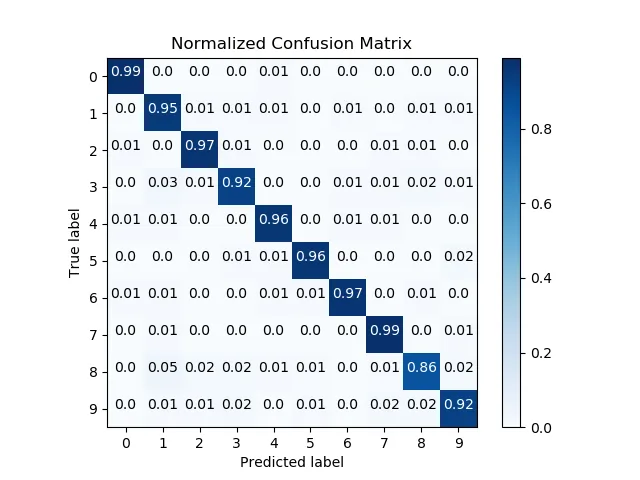
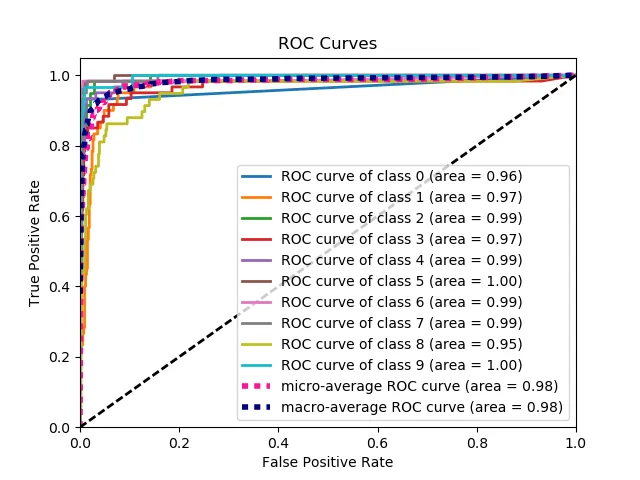
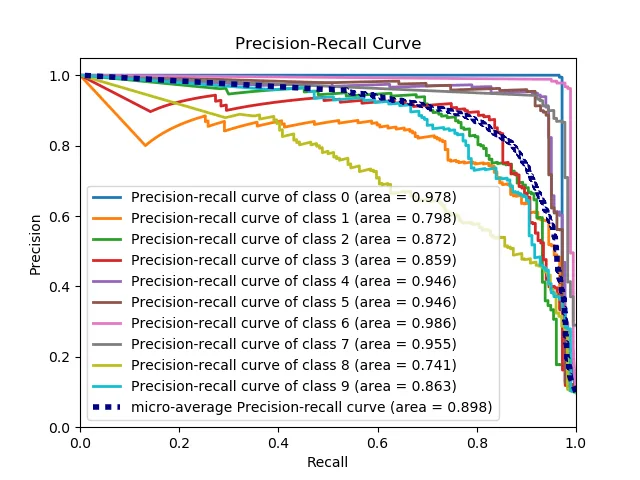
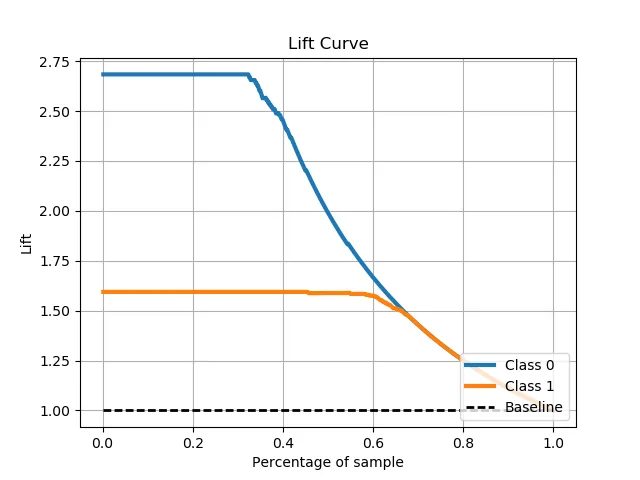
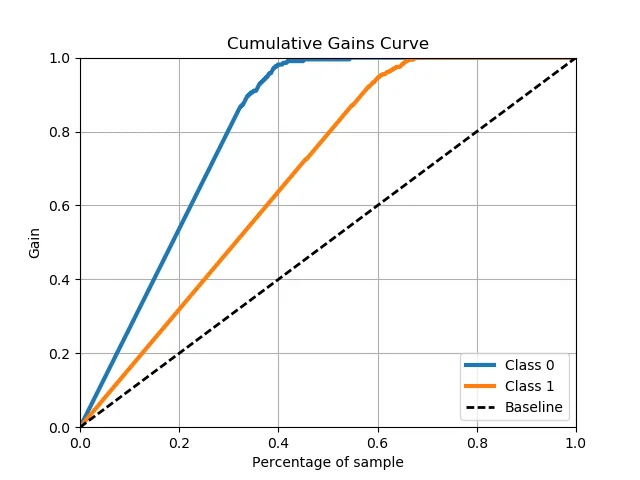
Natural Language Processing Packages
Natural language processing (NLP) is my specialty within data science. There's a lot you can accomplish with Scikit Learn for NLP, which I'll quickly mention below, but there are two additional libraries that can really help you level-up your NLP project.
Scikit Learn
CountVectorizer or TfidfVectorizer make it easy to transform a corpus of documents into a term document matrix. You can train a bag of words classification model in no time when you combine these with LogisticRegression.
Scikit Learn also provides LatentDirichletAllocation for topic modeling with LDA. I like to pair it with pyLDAvis to produce interactive topic modeling dashboards like the one below.

Screenshot of an interactive topic modeling dashboard generated by pyLDAvis.
Spacy
Industrial strength natural language processing
Spacy is really powerful, and in my opinion supersedes the NLTK package that used to be the gold standard for things like part of speech tagging, dependency parsing, and named entity recognition.
Spacy does all of those for you in one line of code without any NLP knowledge. And it's extensible to add your own entities and meta data to spans of tokens within each document.
And the displacy visualization tool is just awesome. Check out this slideshow of examples.

Named entity recognition with spaCy and displacy
* 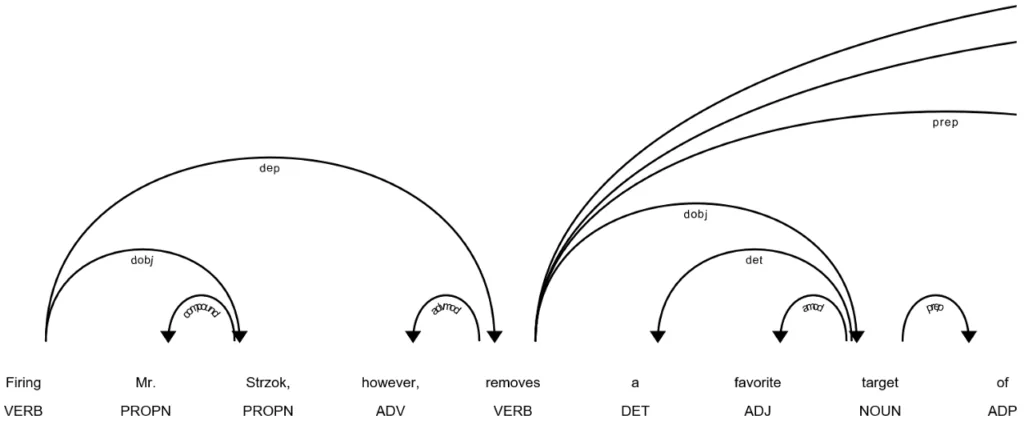
Part of speech tagging and dependency parsing with spaCy and displacy
Transformers
? Transformers provides general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch.
State-of-the-art language models such as BERT and GPT-3 are trained with a neural network architecture called "transformers." The Transformers library by Hugging Face allows you to apply these pre-trained models to your text data.
By doing so, you can generate vectors for each sentence in your corpus and use those vectors as features in your models. Or if your task is one that Transformers supports, you can just apply a complete model and be done. They currently support the following tasks.
- Sequence classification
- Extractive question answering
- Language modeling
- Named entity recognition
- Summarization
- Translation
Deep Learning Packages
Deep learning in Python is dominated by two packages: TensorFlow and PyTorch. There are others, but most data scientists use one of these two, and the split seems roughly equal. So if you want to train a neural network, I recommend picking TensorFlow or PyTorch.
TensorFlow
An end-to-end open source machine learning platform
I use TensorFlow for all of my deep learning needs. The Keras high-level wrapper, which is now incorporated into TensorFlow 2.0, was what sold me on TensorFlow. It's intuitive, reasonably flexible, and efficient.
TensorFlow is production ready with the TensorFlow Serving module. I've used it in combination with AWS SageMaker to deploy a neural network behind an API, but I wouldn't describe TensorFlow Serving as particularly easy to use.
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment
I've never personally used PyTorch (except as a backend for the Transformers library), so I probably won't do it justice here. I've heard it described as more popular in academia. That quote above from their website suggests they are trying to change that image.
But my understanding is that PyTorch offers a bit more flexibility for designing novel neural network architectures than does TensorFlow. So if you plan to do research on new architectures, PyTorch might be right for you.