AI Search Will Break the Internet

Get an email when we publish a new post. No account needed, unsubscribe anytime.
The Contract
Since the dawn of the Internet, the basic contract between search engines and content creators has been this:
- Search engines freely collect content from creators' websites
- Search engines pass users along to that content for free
Content creation makes economic sense when search engines send large amounts of free traffic that can be converted to ad revenue by the creator.
Search engines make economic sense when they can run ads on search result pages.
It's Broken
This model worked until now because search engines were essentially document search engines. They merely forwarded traffic along to the source.
AI breaks this model because Large Language Models can 1) compress knowledge and 2) extract it in arbitrary forms. In other words, LLMs can answer user search queries directly, either by recalling their training data or analyzing one or more new documents. The result is that users of AI-enabled search have no need to visit the website of the source document.
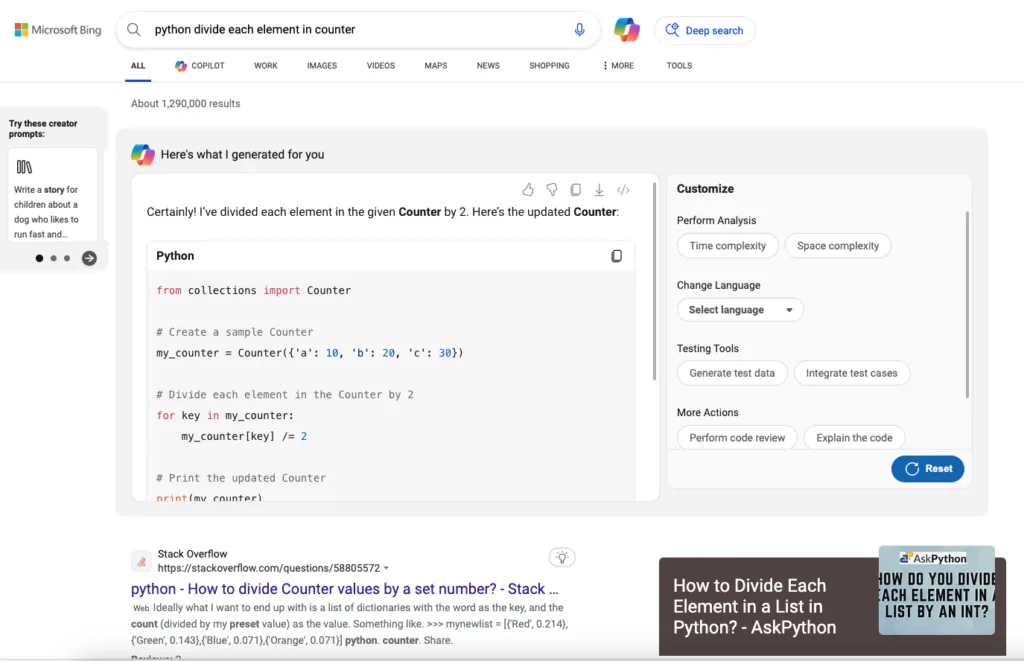
Example of Bing generating an answer to my search query. I didn't need to visit Stackoverflow to get my answer. They lost my ad revenue. Note that I never opted-in to receive AI-generated answers; Bing defaulted to this behavior.
Raw Deal
But long before recent advances in generative AI, search engines have been incrementally adding widgets to search result pages that directly answer users' questions, without the need to click links. This keeps users in front of the search engine’s ads and away from those of content creator. GenAI and web-scraping RAG (Retrieval Augmented Generation) systems are just the final evolution of this long trend.
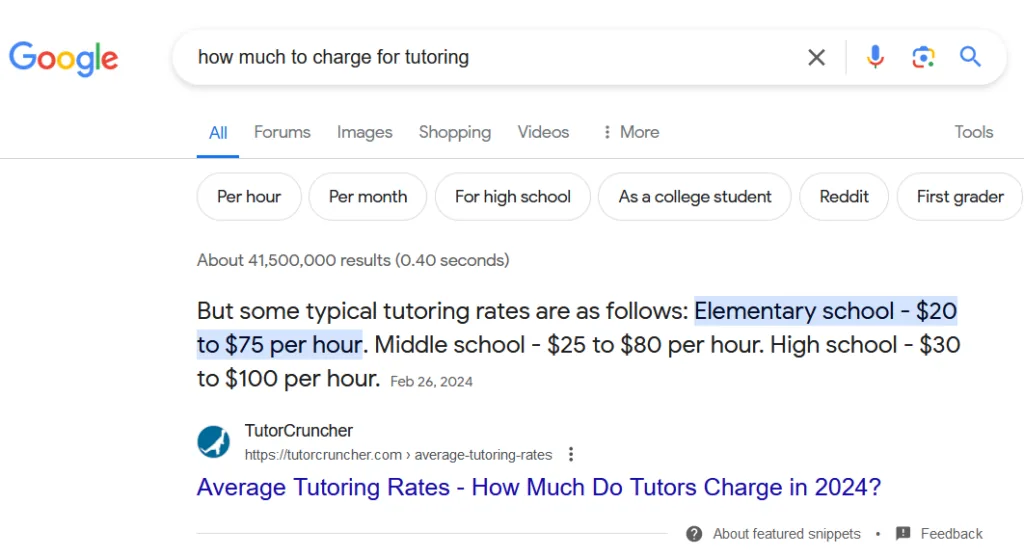
Example of Google answering a user query with a more traditional, extractive question answering method instead of genAI. Widgets like this are not new - back in 2016 I had a popular article that Google had extracted a similar answer from for the same query.
So actually this contract between search engines and creators has always been a raw deal. Search engines generate their own ad revenue before users are ever sent to the source. And they have always used the latest technology available to directly answer as many questions as they can instead of forwarding traffic to the source.
I claim that the vast fortunes of Google and other search engines are fundamentally plundered from the hard labor of content creators. The ad revenue generated on search result pages should have been shared all along with the creators whose content makes up those results.
Lawsuit
Although the "contract" described above has been breached, it of course is not a real, legal contract. However, I would argue (with my very limited legal knowledge) that publishers have a case for a class action lawsuit against search engines for copyright infringement due to illegal redistribution.
Google and others have siphoned billions from creators and will continue to take an ever increasing share of ad revenue from creators as advancements in AI continue, all built on top of the most massive copyright infringement abuse in human history. Search engines illegally redistribute content without full compensation to creators.
Bad Faith
Google's new Head of Search, Liz Reid, was recently quoted by The Verge as saying:
Google will increasingly trade links for answers — and Reid has acknowledged that figuring out how to cite those answers, and continue to be a good partner to the open web, is part of her ongoing challenge.
But can the open web really trust her, and Google as a whole, to do right by creators? When they've been slow walking towards answers instead of links for a decade? When the ads on their search result pages, populated by content not owned by Google, generate $86B in profit annually that is never seen by creators?
In light of all this, it becomes suddenly clear why Google and Microsoft have made the biggest investments in genAI, and why everything they do is closed-source.
Risks
This is a risk to journalists, writers, and any business whose product is written knowledge. When AI enables search engines to deliver answers instead of links, websites lose their primary source of traffic to generate ad revenue.
When the rules change and the interests of search giants and content creators no longer align, we can't just sit back and hope that the search giants do right by content creators given how asymmetrical the balance of power is and given the bad faith they've already shown.
Remedies
Enforcing copyright laws at the scale of Google is difficult. If publishers did decide to pursue search engines in court, perhaps some lawsuits could be won or settled years from now that might offer a pittance to a sliver of the creator pool.
By then genAI will have so radically changed the way people find information that search result pages will feel like land-line phones.
And if search engines are forced by the courts to somehow share ad revenue on SERPs with publishers, enforcing compliance would be a logistical nightmare, probably requiring independent auditing agencies.
Solutions
We need new business models that help realign interests and/or shift the balance of power. Companies like TollBit are taking a stab at that, and I believe we need much more innovation in this space.
What the world needs is a content distributor built from the ground up to be transparent, fair, and compliant — a sustainable search company built for the AI age that provides proper incentives to creators and a superior experience for users.
AI offers value that many users are willing to pay for, unlike traditional document search engines. And of course AI search still has plenty of opportunity for ad placements, ethical concerns not withstanding.
Creators’ content distribution should be transparently tracked with usage-based compensation. Ad revenue and time-weighted share of subscription revenue (a la Medium or Spotify) should be shared with creators. And this needs to be a revenue share for usage within the application, not merely forwarding traffic. Every answer needs to cite it's source and compensate that source, whether the user visits it or not.
An organization that creates such an ecosystem should be built with a foundation of openness, including usage of open source LLMs and an open web index accessible via tolling to compensate creators.
Competition
Google is a monopoly with immense power. The livelihood of every journalist in the West is dependent on search traffic sent from Google. What happens when that fire hose of traffic slows to a trickle? Who will fund the journalism needed for a well-functioning society? Would Google just start acquiring media companies...?
The world needs to break out of this vicious cycle, and we can't wait for incumbents to solve it for us.
I believe our best hope is to build a radically open and transparent AI-powered search engine that competes directly with Google and Bing. For all their immense power, they do still have a potentially fatal flaw: they are closed. They have closed-source web indexes and closed-source LLMs. When the creators that feed those beasts stop trusting that doing so serves their own interests, the beast will starve.