Where are all the generative AI job postings?
Get an email when we publish a new post. No account needed, unsubscribe anytime.
Blog Data vs Job Data
Let's start with the data. The analysis I'll describe below is a comparison of two data sets.
- 1,523 data science articles scraped from various sources by Skillenai spanning June 1st 2023 through July 5th 2023.
- 2,003 job postings scraped and processed by Luke Barousse for datanerd.tech, spanning the exact same time period.
I'm super excited to be collaborating with Luke on some NLP for his 1M+ data set of data job postings. More to come on that in subsequent posts. But Luke is the one who discovered the conspicuous absence of AI tool mentions in his job data set, and now I'm adding additional context to that discovery with my data science blog data set.
Skill Extraction
Problem Statement
To make an apples to apples comparison between the blog data and the job data, I needed a way to extract skills, tools, programming languages, and the like from text documents that could work on both job descriptions and blog articles.
I wanted to avoid a keyword-based approach because 1) there are a large number of skills relevant to data science and 2) I plan to continuously monitor trends in new tooling, so I can't rely on a static list of keywords.
Named Entity Recognition
This problem is well suited for named entity recognition (NER), which identifies which words in a document refer to various entity types. In this case I would need a custom entity type for SKILL and maybe others like PROGLANG or TOOL. No off-the-shelf NER model provided by the likes of spaCy and Flair include a SKILL entity type.
I started with a search on HuggingFace for pre-trained NER models for extracting job skills. I was initially impressed with the quantity of available options, including a fine-tuned Flair model for skills, but quickly became discouraged with the quality. Most of them were relying on huge static lists of keywords, exactly what I wanted to avoid. And the ML-based options just didn't produce good results for my test cases.
Generative AI
Training or fine-tuning my own NER model would only be economical for me if the training data was generated by ChatGPT (can't afford the time or money to hand-label 100s or 1000s or documents). Luckily, for my current use case, a small sample is sufficient to discover some trends and insights.
I calculated that it would cost around $10-$20 to use GPT3.5 to extract skills from all 1,523 data science articles and 2,003 job descriptions. So I decided to just use ChatGPT outputs directly and cut out the NER training entirely.
After some trial and error, I landed on the prompt below. The results are quite good and meet all of my requirements and budget.
You are a job skill extraction bot. Users will provide you with a document such as a job description, resume, or blog article, and you will extract all the job skills, then respond with a Python dict with keys for "Techniques", "Programming Languages", "Tools", and "Tasks" and with values as lists of strings. Your response is always only this Python dict with no other text before or after to explain the response. Always respond in English even if the job posting is in a different language. Here are some examples of "Techniques": machine learning, natural language processing, predictive modeling, regression. Here are some examples of "Programming Languages": Python, SQL, R, Java, Javascript. Here are some examples of "Tools": pandas, numpy, scikit-learn, spaCy, airflow, aws, azure, mysql, elastic search. Here are some examples of "Tasks": machine translation, named entity recognition, text-to-image, question answering, image segmentation.
Skill Analysis
Before getting into the comparison of job skills vs blog skills, let's take a quick look at the top job skills extracted via ChatGPT vs extracted via keywords. First I'll show the ChatGPT results. Note that I've merged "Techniques," "Programming Languages," "Tools," and "Tasks" into one complete list of skills for each job posting. Here is a count of job postings mentioning each skill (out of 2003).
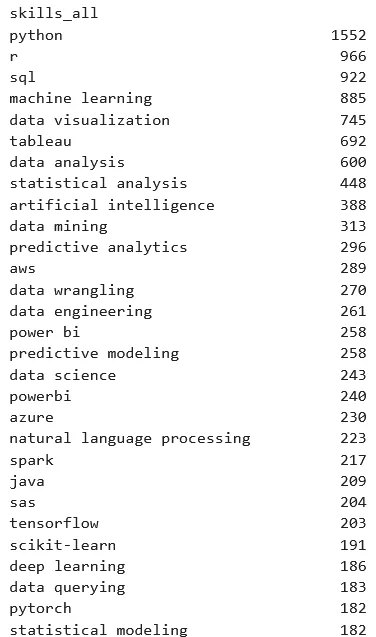
Job Skills All - ChatGPT Generated
And here's the skills extracted via keywords (Luke created the keyword lists and applies them in his job processing pipeline).
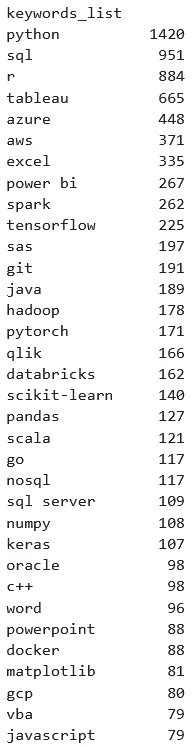
Job Skills All - Keyword Generated
Luke's keyword list is great, but it really focuses on programming languages and tools. And the same was true for the lists I found on Hugging Face. I can imagine why - it's just really hard to build keyword lists that cover a diverse set of techniques and tasks. But I'm really interested in items like NLP, ML, AI, CV, data viz, etc. so I'm very excited that ChatGPT was able to extract those for me.
Skill Comparison: Blogs vs Jobs
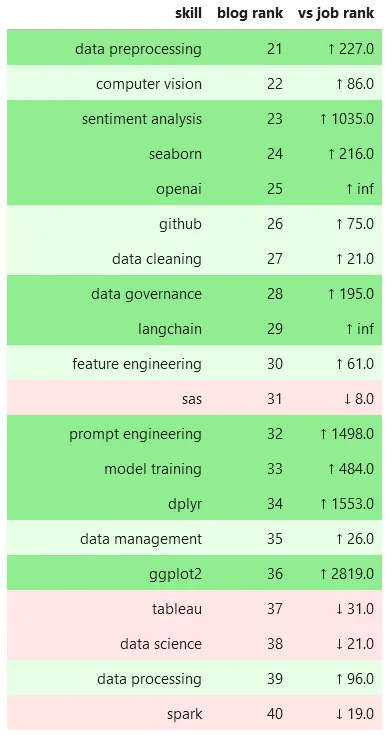
Now, without further ado, I present to you a comparison of rankings of top mentioned skills in blogs vs job descriptions. Be sure to click through the carousel to see more.
Top Data Science Skill Mentions in Blogs vs Jobs - Top 20
* 
Top Data Science Skill Mentions in Blogs vs Jobs - Top 21-40
* 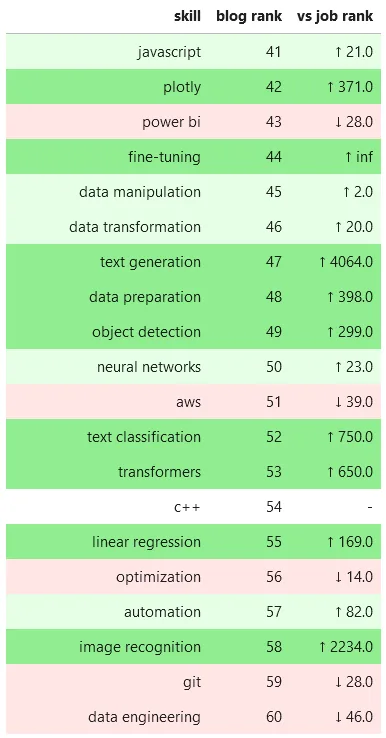
Top Data Science Skill Mentions in Blogs vs Jobs - Top 41-60
There's so many interesting stories to tell with this data, but the most striking and unexpected result to me is this: literally every item related to generative AI (chatgpt, generative ai, openai, langchain, prompt engineering, and text generation) is either non-existent in the jobs data set or has a ranking in the thousands!
Why Don't Data Science Job Postings Mention Generative AI?
It's been almost a year since ChatGPT and Stable Diffusion took the world by storm. The data science community has been frantically writing about them in hopes of learning 1) how to use them, 2) maybe how to build them, and 3) how they will impact our careers.
Yet data science hiring managers seem to be pretending that nothing has changed. They're still fixated on "data mining," "predictive analytics," and "data wrangling" like it's 2010. Here's the reverse of the skill ranking differences, with the job skills as the base.
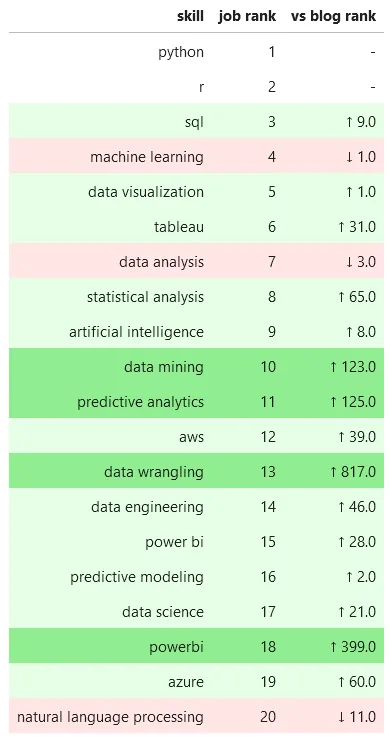
Top Data Science Skill Mentions in Jobs vs Blogs - Top 20
Hiring Manager Perspective
As a hiring manager, I can posit one potential reason for this odd situation. See, when a new role opens up, it doesn't mean that a new job description will be written. Rather, the template you used for the last role will be recycled and very slightly modified for the level or focus area. This means that in some organizations, job descriptions posted today may literally have been written in 2010.
Now, speaking as one hiring manager to another, I believe it's time we begin coming to grips with the changing landscape of the data science field. Generative AI is here to stay, and we better make sure we're hiring people that know how to use it.
I for one did recently update my team's job description template to include generative AI techniques and tools. If you're not sure what skills to ask for, feel free to use something like this.
Experience with generative AI techniques and tools such as OpenAI's ChatGPT, Large Language Models (LLMs), Hugging Face, and Langchain.
What do you think?
But what do you think? Do you think generative AI is overlooked in job postings merely because of recycled job description templates, or is something else at work here?
Maybe generative AI is just hype and data science leaders don't see it being useful for solving real business problems? Should we as data scientists get back to basics and stop playing so much with our shiny new toy?
Learn More
If you're interested in benefiting from the data science blog data set compiled by Skillenai, head over to our email digest page to learn more.
And thanks again to Luke Barousse for sharing this amazing jobs data set with me. To learn more about that data, head over to the datanerd.tech app to explore more skills and salary insights.