What Does a Data Scientist Do?
Get an email when we publish a new post. No account needed, unsubscribe anytime.
Why Data Science Is a Good Career
Data science is one of the best careers for highly technical individuals. It offers a clear path to a salary above $100,000 within 5 years. It also offers a chance to solve challenging problems, work with multi-disciplinary teams, and make a big impact.
Similar Roles That Get Confused with Data Science
The skills required of a data scientist overlap with many other roles. But there are key differences between data science and these roles in both emphasis and level of expertise required for each skill.
Here are some similar roles that often get conflated with data science.
- Business Intelligence Analyst
- Similarities: Both roles require analyzing data and building predictive models.
- Differences: BI analysts are more focused on visualization and dashboards. They are also more consultative, often working with internal stakeholders to deliver insights. In contrast, data scientists are more focused on building models for production use cases (i.e. for external customers).
- Data Engineer
- Similarities: Both roles require building extract, transform, load (ETL) pipelines. They also both require knowledge of databases and big data.
- Differences: Data engineers are exclusively responsible for building and maintaining data pipelines and data stores. Data scientists, in contrast, may build their own data pipelines but only as a means to an end for their model pipelines.
- Machine Learning Engineer
- Similarities: Both roles require knowledge of machine learning software, along with tools for deploying models to production.
- Differences: ML engineers are exclusively responsible for deploying and maintaining production models and pipelines. Data scientists are often expected to deploy their own models as well, at least in low-volume contexts. But for larger scale products or companies, data scientists may focus on research and development while ML engineers focus on production.
- Software Engineer
- Similarities: Both roles require knowledge of coding best practices.
- Differences: Software engineers are experts in software, often at a much lower or more conceptual level than data scientists. But coding best practices are critical for every data scientist.
- Research Scientist
- Similarities: Both roles require scientific rigor and data analysis.
- Differences: Research scientists generally perform research that pushes boundaries. Their work typically results in either publications or application of cutting-edge research to industry problems. Data scientists are focused on solving the highest-value business problems, which may or may not require novel approaches.
- Data Analyst / Business Analyst
- Similarities: Both apply analytical techniques to understand trends in data.
- Differences: Data analysts generally perform descriptive analyses that summarize historical data. Data scientists generally perform predictive analyses that forecast future outcomes or predict behavior in never-before-seen circumstances.
What Data Scientists Don't Do
Before we dive into what data scientists do, let's talk about what data scientists don't do.
- SQL all day
- SQL is a powerful language for extracting and analyzing data stored in relational databases. Every data scientist should be proficient in SQL. But if you're writing SQL all day, you're probably either a Data Engineer (building data pipelines) or a Business Analyst (pulling data for descriptive analysis).
- Excel all day
- Excel is powerful, too, and certainly has it's place in some data science workflows. But Excel is terrible for automation and reproducibility. It also lacks machine learning capabilities, to the best of my knowledge. If you're serious about entering the field of data science, start learning Python or R right away.
- Prototyping all day
- Prototypes are invaluable for proving a concept and getting buy-in for a new feature or product. But data scientists must inevitably write production code and deploy models to production. Contrary to the beliefs of some software engineers, not all data science code is prototype-quality.
- Academic research
- Some data science roles have research components and lead to publications. And most data scientists must spend a non-trivial proportion of time experimenting with approaches that may ultimately lead to dead ends. But data science is not an academic exercise; at the end of the day, the goal must be to deploy models to production (and to maintain until end of life).
- Web development
- It's often useful for data scientists to be familiar with web architectures and frameworks. And in the prototyping phase, it's not unusual for a data scientist to create a simple web app. But building websites or apps is not a core responsibility of most data scientists.
What Data Scientists Do
Now that we know what a data scientist doesn't do, let's finally answer the titular question: what does a data scientist do? There are two famous definitions of data science that I'll introduce first.
The Tweet
https://twitter.com/josh_wills/status/198093512149958656?lang=en
The famous data science definition by Josh Wills
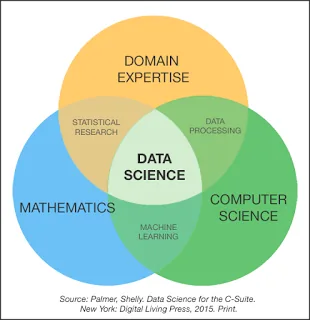
The Venn Diagram
The famous data science skill set Venn diagram
The Gist
The gist of both of these definitions is this: data science is a hybrid field combining elements of statistics, software, and business. It's inherently multi-disciplinary.
It's worth noting something that may be obvious. It's difficult for individuals to be proficient in all three disciplines. And it's valuable for a company to have one person capable of doing work in all three. This is what drives low supply and high demand for data scientists in the labor market, contributing to a stubborn shortage that has persisted for years.
The Details
Now let's drill into more details about what, specifically, data scientists do.
Data Science Foundations
If I were to teach a data science bootcamp, I would cover the following foundational topics. (Similarly, if I was a student, I would look for a program with the following topics in the curriculum.)
- Software Engineering
- Python
- Basics, numpy, pandas, scikit-learn, matplotlib
- Coding standards - PEP 8, OOP, abstraction, modularity
- Parallelization, profiling
- Cloud
- AWS - S3, EC2, SageMaker, Lambda
- Deployment
- Flask, SageMaker
- Python packaging, dependency management
- Testing
- SQL
- SELECT, JOIN, GROUP BY, WINDOW
- Unix
- Navigation, file manipulation, cron, screen, git
- Git
- Pull request workflow, code reviews
- Development
- Jupyter, IDEs - Atom, vscode
- Repo templates
- Modeling
- Regression
- Linear regression
- Classification
- Logistic regression
- Clustering
- K-means
- Ensembling
- Random forest, Gradient boosted trees
- Other algorithms
- Naïve Bayes
- SVM
- Collaborative Filtering
- Multi-layer perceptron
- Visualization
- Matplotlib, seaborn
- Big Data
- Parallelization with joblib and multiprocessing
- Memory limits
- Spark
- Model Selection
- Pipelines
- Hyperparameter tuning
- Cross validation
- Exploratory Data Analysis
- Statistics
- Hypothesis Testing
- Model Evaluation
- Metrics
- Experimental design
- Data quality checks
- Business / Domain
- Feasibility Studies
- Choosing a target
- Prototyping
- Acquiring input data
- Annotating data
- Data Dictionaries
- Agile
- Assessing level of effort
- Business communication
- Your responsibility to make people understand
- Executive summaries
- Briefs
- Setting expectations
- Relationship with subject matter experts
- Relationship with product managers
- Relationship with customers / clients
- Relationship with software engineers
- Balancing short-term business value and research
- Breakthroughs vs incremental progress
- Helping business team understand uncertainty and non-linearity
- Success not guaranteed, may be dependent on breakthroughs
- Balancing interpretability and accuracy
- Defining business metrics
- Levels of maturity
- Modeling efforts progress through different levels of maturity, each needs to be managed accordingly
Advanced Topics
Finally, let's just mention some of the advanced topics in the field of data science that you may have heard as buzz words. Each of these topics could be considered a specialization within data science, to be mastered once you're proficient in all of the foundations. I'll leave descriptions of each for future posts.
- Deep Learning
- Natural Language Processing (NLP)
- Computer Vision
- ML Engineering
- Big Data
- Time Series
- Fraud and Anomaly Detection
- Personalization
- Reinforcement Learning
- Data Science Leadership
Become a Data Scientist
So those are the things a data scientist does every day. No one said it was easy. But I will say that it's a ton of fun, and an extremely rewarding career.
There's always more to learn, and that's why Skillenai was born - to help every data scientist at every level continue growing their career.
Stay tuned as we add tutorials for all of the topics mentioned here and beyond.