How to Improve a DAG
Get an email when we publish a new post. No account needed, unsubscribe anytime.
What is a DAG?
DAG stands for directed acyclic graph. In the sphere of data engineering, you will often hear DAG thrown around as though it is synonymous with a data pipeline; it is actually a more general mathematical concept. Data pipelines fit the definition of DAG, but not all DAGs are data pipelines. Data pipelines are DAGs because they are:
- Directed, because there is a defined, non-arbitrary order of tasks
- Acyclic, because they never make circles since that would mean they run forever
- Graph, because their visual representation consists of nodes and graphs
A non-math example of a DAG is family trees (Wikipedia). So DAGs exist all around us, but what makes them good or bad in the world of data pipelining?
A note on terminology: mathematically, a DAG consists of nodes (the circles) and edges (the straight lines), but in this post, I will be referring to the vertices as "tasks". This is what they are called in Apache Airflow, and this more accurately describes their function as a "unit of work within a DAG" (Source).
What is a bad DAG?
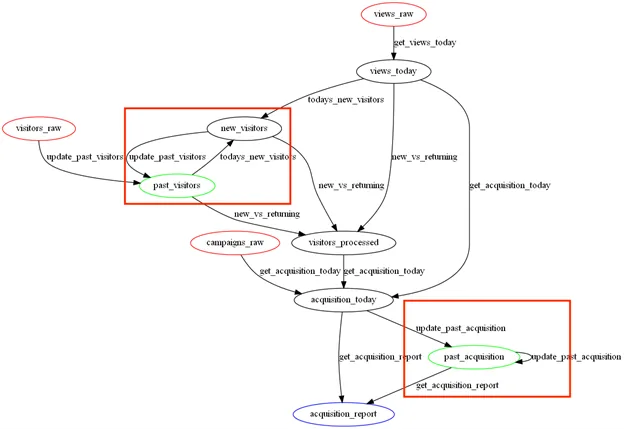
There is no definition for what makes a bad DAG, but there are attributes of a DAG that can cause inefficiencies. Jared designed the "worst data pipeline ever" to display some of the common pipeline design mistakes:
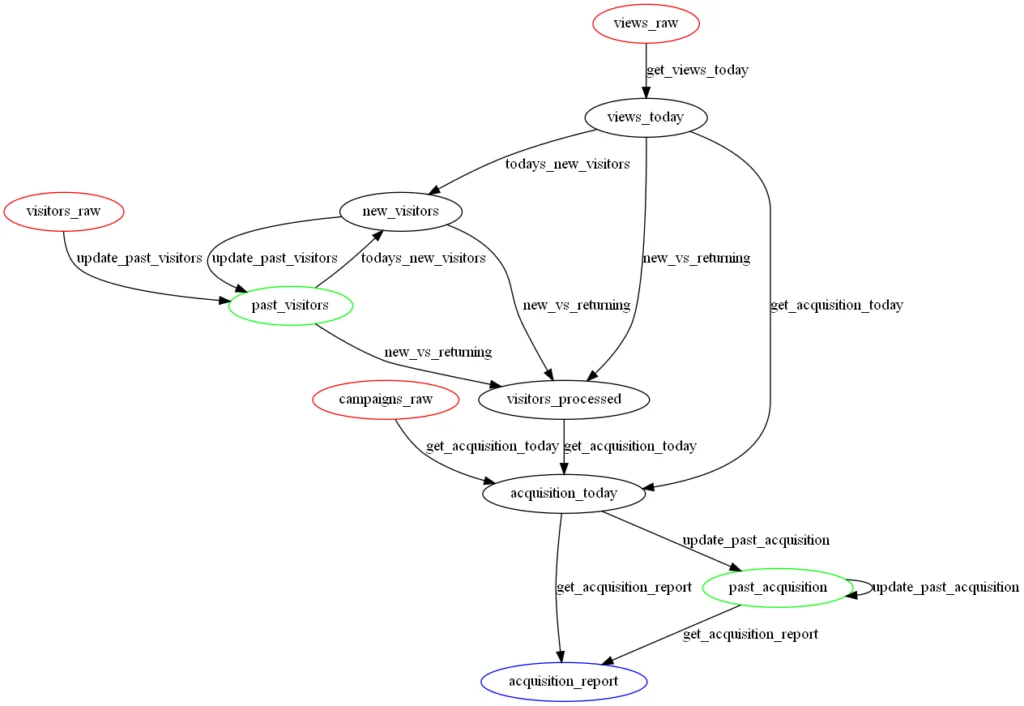
Image credit – Worst data pipeline ever
{kind=link}
How do we improve a bad DAG?
Cycles
A DAG can be so bad that it is not even a DAG; in this case, the data pipeline has cycles so it is not acyclic. The cycles in this pipeline are highlighted below:
Image by author - Worst data pipeline, with cycles
If this pipeline were coded in an Airflow DAG file, the Airflow webserver would not render it visually nor run it. It would display the error: "Cycle detected in DAG".
It is hard to say how to fix these cycles without seeing the data, the flow of past_acquisition -> past_acquisition should be combined into one task. The one thing I would caution about is to not solve this by copying the past_acquisition twice. That cycle has to be eliminated by entirely refactoring the code to handle the update.
The same is true for the new_visitors -> past_visitors -> new_visitors. The cycles have to be eliminated within the code.
Dependencies
Although I don't know the data associated with this DAG, it looks like the underlying architectural issue here is one of database design. Specifically, views, visitors, and campaigns are their own entities and should have some sort of physical manifestation before code is built on top of them to produce the reporting table acquisition_today. Assuming that the acquisition_today report was the one requested by stakeholders, it is natural to want to build the DAG around it. After all, what use is a DAG if it doesn't produce something that the stakeholders want?
We do want to produce the report, but we want to do it as efficiently and scalable as possible. The inefficiency of this dag is easiest to explain with a hypothetical situation: if there is an error in views_today and we fix it, in order to update the report, we have to re-run all downstream tasks. This impacts all but three tasks: views_raw, visitors_raw, and campaigns_raw. This is time consuming (as stakeholders wait anxiously for their data) and compute intensive. If past_visitors is mostly visitor-based data with one or two fields from views, re-running past_visitors because of a views change is inefficient.
Additionally, not having a visits or campaign entity makes it hard to debug changes to acquisition report. If a stakeholder notices the report has a sharp increase in visits, can they quickly isolate those visits for quality assurance? If the report shows 30 visits yesterday and 100 today, can they find the new visit_ids easily to look it up in the source system? When all building blocks of a report are materialized to stakeholders, they have more agency to both understand and debug the data, taking work from the data engineering team.
Lastly, history tells us that stakeholders may want more than one report off this data or a change in reports. If stakeholders request a funnel_report, using the views data but not the campaign data, this DAG does not give us the flexibility to do that. Therefore, we want to build out all the underlying entities and then combine them at the very end.
What makes a good DAG?
Below is a good dag. Notice that:
- There are no cycles
- All entities are materialized independently (campaigns, visitors, views, etc) before being combined into the acquisition_report
- We are able to add several reports (funnel_report, customer_profile) from the same entities
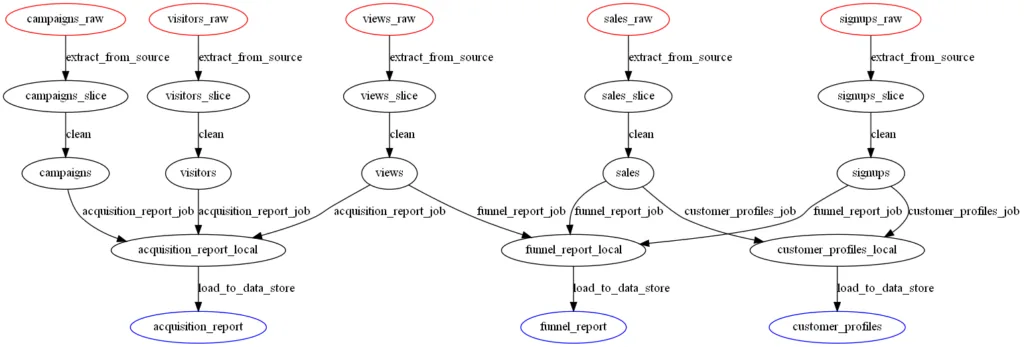
Image credit – A better data pipeline
{kind=link}