Tailoring LLMs: A Guide to Fine-Tuning for Specific Tasks

Introduction: Why Fine-Tune Pretrained Models?
In the realm of Natural Language Processing (NLP), Large Language Models (LLMs) like GPT-3, BERT, and LLaMA have revolutionized the way machines understand and generate human language. However, while these models are trained on vast datasets, they might not always align perfectly with specific tasks or domains. This is where fine-tuning comes into play.
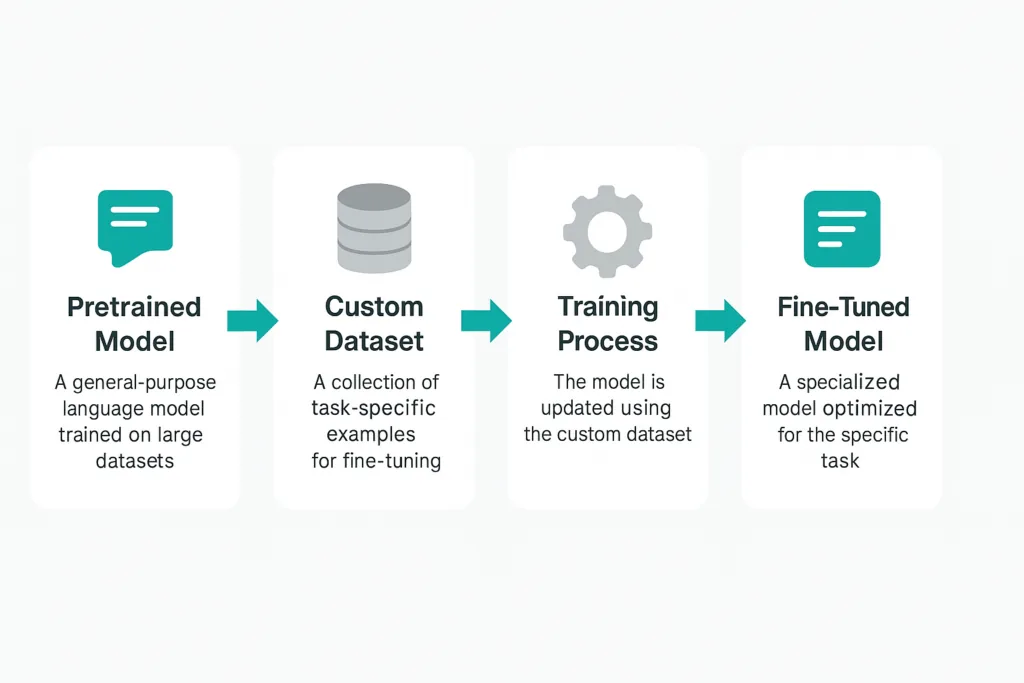
Fine-tuning involves taking a pretrained model and adapting it to a particular task using a smaller, task-specific dataset. This approach leverages the general language understanding of the pretrained model and refines it to perform better on specialized tasks, such as sentiment analysis, question answering, or domain-specific text generation.
Understanding Transfer Learning and Its Importance
Transfer learning is the foundation of fine-tuning. It allows models to apply knowledge gained from one task to different but related tasks. By fine-tuning a pretrained model, we utilize its existing language understanding and adjust it to better suit our specific needs, saving both time and computational resources compared to training a model from scratch.
Step-by-Step Guide to Fine-Tuning LLMs
1. Selecting the Right Pretrained Model
Choose a model that closely aligns with your task. For instance, if you're working on a text classification task, models like BERT or RoBERTa might be suitable. For text generation, GPT-based models are often preferred. Platforms like Hugging Face's Model Hub offer a plethora of pretrained models to choose from.
2. Preparing Your Dataset
Your dataset should be formatted to match the requirements of your chosen model. For classification tasks, this typically involves pairs of input texts and corresponding labels. Ensure your data is clean, balanced, and representative of the task at hand.
3. Setting Up the Environment
Utilize libraries like Hugging Face's Transformers and Datasets to streamline the fine-tuning process. Ensure you have the necessary computational resources, such as GPUs, to handle the training efficiently.
4. Fine-Tuning the Model
Here's a simplified example using Hugging Face's Transformers library:
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Load dataset
dataset = load_dataset('csv', data_files={'train': 'train.csv', 'test': 'test.csv'})
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Tokenize dataset
def tokenize_function(example):
return tokenizer(example['text'], truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Define training arguments
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='epoch',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=64,
logging_dir='./logs',
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
)
# Train the model
trainer.train()
This script demonstrates the process of fine-tuning a BERT model for a binary classification task. Adjust the parameters and dataset paths as needed for your specific use case.
5. Evaluating Model Performance
After fine-tuning, it's crucial to assess the model's performance using appropriate metrics such as accuracy, precision, recall, and F1-score. This evaluation helps determine how well the model has adapted to the specific task and whether further adjustments are necessary.
Practical Example: Fine-Tuning for Sentiment Analysis
Suppose you have a dataset of customer reviews labeled as positive or negative. By fine-tuning a pretrained BERT model on this dataset, you can create a sentiment analysis tool tailored to your specific domain, such as product reviews or service feedback.
Tips for Effective Fine-Tuning
- Start with a smaller learning rate: Fine-tuning requires subtle adjustments; a smaller learning rate prevents drastic changes to the pretrained weights.
- Use early stopping: Monitor validation loss to prevent overfitting.
- Experiment with different batch sizes: Depending on your hardware, adjusting the batch size can lead to better performance.
- Leverage data augmentation: Enhancing your dataset with paraphrased or slightly altered examples can improve model robustness.
Conclusion
Fine-tuning pretrained LLMs is a powerful technique to adapt general-purpose models to specific tasks, offering improved performance without the need for extensive computational resources. By following the steps outlined above and tailoring them to your unique requirements, you can harness the full potential of LLMs for your applications.